High availability is a high percentage of time that the system is working and responding according to the business needs. For production database systems it is typically the highest priority to keep it close to 100%. We build database clusters to eliminate all single point of failure. If an instance becomes unavailable, another node should be able to take the workload and carry on from there. In a perfect world, a database cluster would solve all of our system availability problems. Unfortunately, while all may look good on paper, the reality is often different. So where can it go wrong?
Transactional databases systems come with sophisticated storage engines. Keeping data consistent across multiple nodes makes this task way harder. Clustering introduces a number of new variables that highly depend on network and underlying infrastructure. It is not uncommon for a standalone database instance that was running fine on a single node suddenly performs poorly in a cluster environment.
Among the number of things that can affect cluster availability, latency issues play a crucial role. However, what is the latency? Is it only related to the network?
The term "latency" actually refers to several kinds of delays incurred in the processing of data. It’s how long it takes for a piece of information to move from stage to another.
In this blog post, we’ll look at the two main high availability solutions for MySQL and MariaDB, and how they can each be affected by latency issues.
At the end of the article, we take a look at modern load balancers and discuss how they can help you address some types of latency issues.
In a previous article, my colleague Krzysztof Książek wrote about "Dealing with Unreliable Networks When Crafting an HA Solution for MySQL or MariaDB". You will find tips which can help you to design your production ready HA architecture, and avoid some of the issues described here.
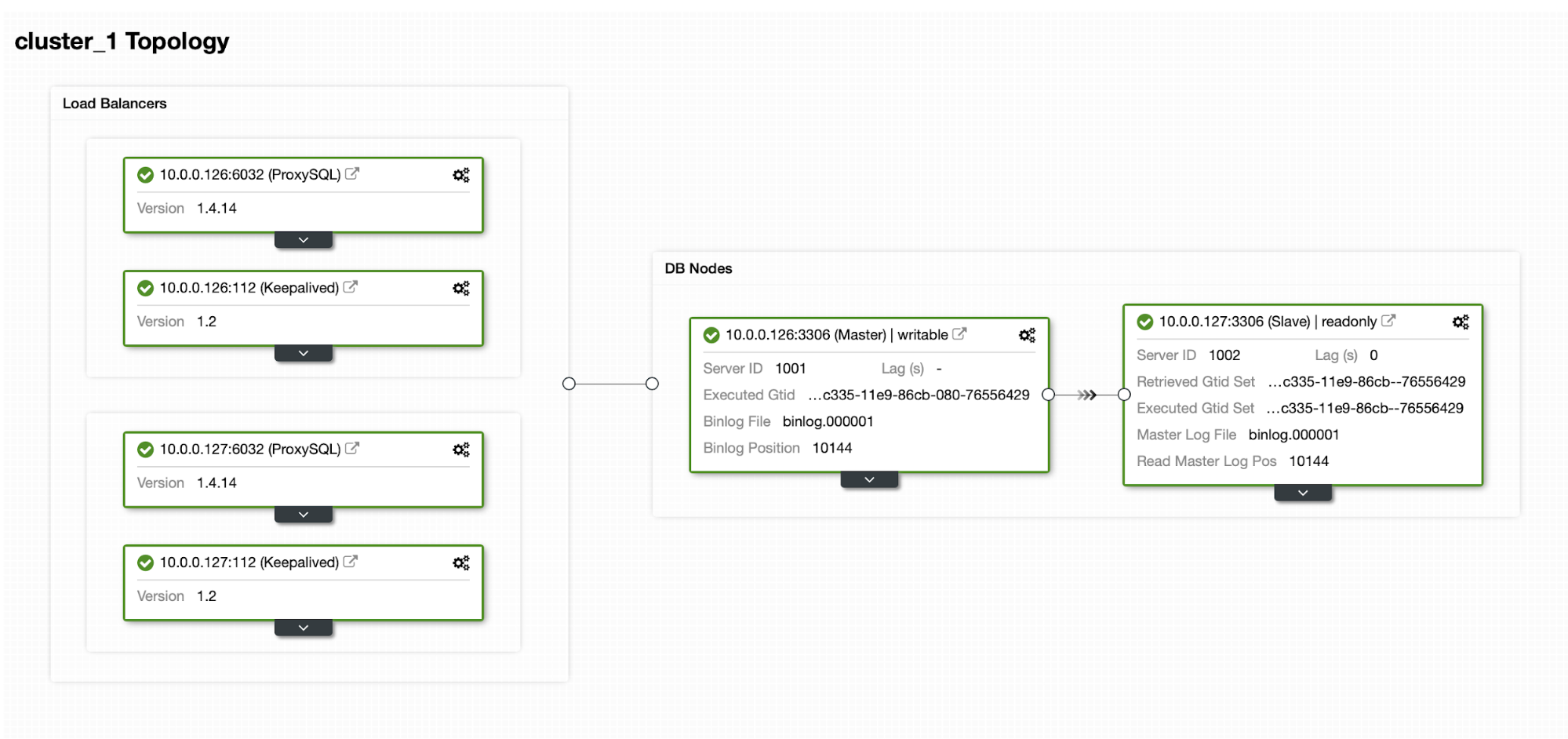
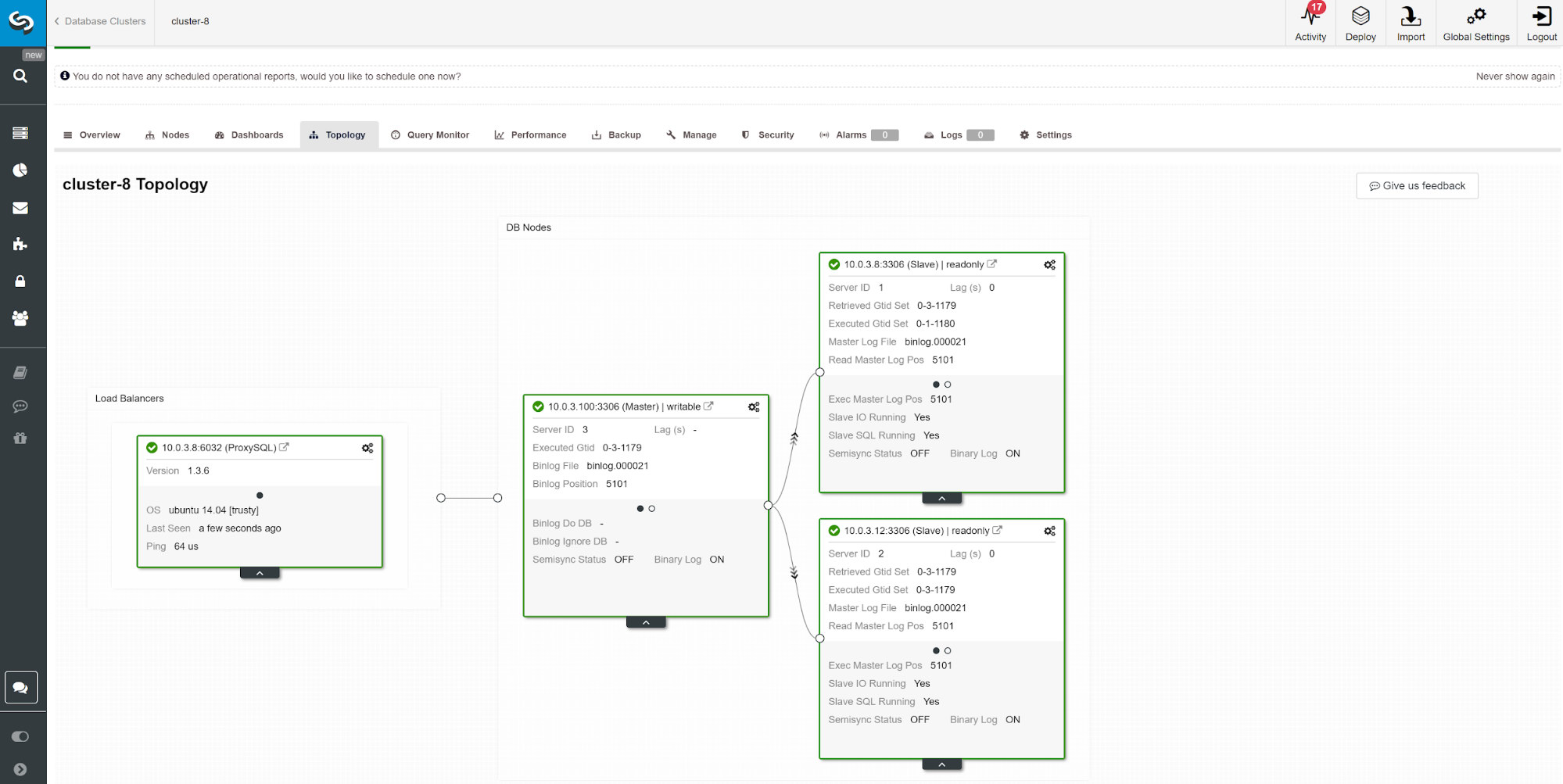
Master-Slave replication for High Availability.
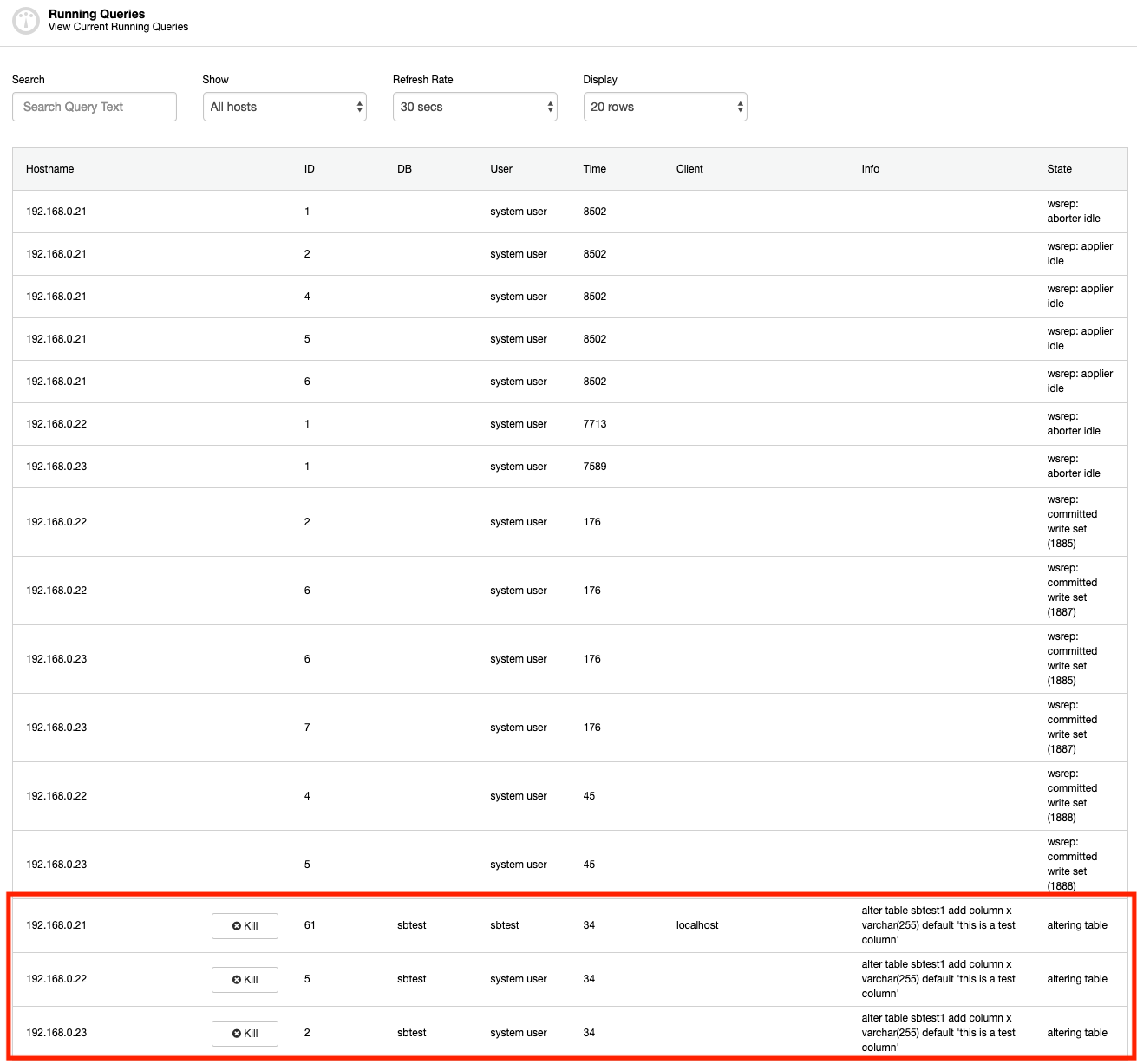
MySQL master-slave replication is probably the most popular database cluster type on the planet. One of the main things you want to monitor while running your master-slave replication cluster is the slave lag. Depending on your application requirements and the way how you utilize your database, the replication latency (slave lag) may determine if the data can be read from the slave node or not. Data committed on master but not yet available on an asynchronous slave means that the slave has an older state. When it’s not ok to read from a slave, you would need to go to the master, and that can affect application performance. In the worst case scenario, your system will not be able to handle all the workload on a master.
Slave lag and stale data
To check the status of the master-slave replication, you should start with below command:
SHOW SLAVE STATUS\G
MariaDB [(none)]> show slave status\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 10.0.3.100
Master_User: rpl_user
Master_Port: 3306
Connect_Retry: 10
Master_Log_File: binlog.000021
Read_Master_Log_Pos: 5101
Relay_Log_File: relay-bin.000002
Relay_Log_Pos: 809
Relay_Master_Log_File: binlog.000021
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 5101
Relay_Log_Space: 1101
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: 0
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 3
Master_SSL_Crl:
Master_SSL_Crlpath:
Using_Gtid: Slave_Pos
Gtid_IO_Pos: 0-3-1179
Replicate_Do_Domain_Ids:
Replicate_Ignore_Domain_Ids:
Parallel_Mode: conservative
1 row in set (0.01 sec)Using the above information you can determine how good the overall replication latency is. The lower the value you see in "Seconds_Behind_Master", the better the data transfer speed for replication.
There are a number of things that can affect replication time. The most obvious is the network throughput and how much data you can transfer. MySQL comes with multiple configuration options to optimize replication process. The essential replication related parameters are:
- Parallel apply
- Logical clock algorithm
- Compression
- Selective master-slave replication
- Replication mode
Parallel apply
It’s not uncommon to start replication tuning with enabling parallel process apply. The reason for that is by default, MySQL goes with sequential binary log apply, and a typical database server comes with several CPUs to use.
To get around sequential log apply, both MariaDB and MySQL offer parallel replication. The implementation may differ per vendor and version. E.g. MySQL 5.6 offers parallel replication as long as a schema separates the queries while MariaDB (starting version 10.0) and MySQL 5.7 both can handle parallel replication across schemas. Different vendors and versions come with their limitations and feature so always check the documentation.
Executing queries via parallel slave threads may speed up your replication stream if you are write heavy. However, if you aren’t, it would be best to stick to the traditional single-threaded replication. To enable parallel processing, change the slave_parallel_workers to the number of CPU threads you want to involve in the process. It is recommended to keep the value lower of the number of available CPU threads.
Parallel replication works best with the group commits. To check if you have group commits happening run following query.
show global status like 'binlog_%commits';The bigger the ratio between these two values the better.
Logical clock
The slave_parallel_type=LOGICAL_CLOCK is an implementation of a Lamport clock algorithm. When using a multithreaded slave this variable specifies the method used to decide which transactions are allowed to execute in parallel on the slave. The variable has no effect on slaves for which multithreading is not enabled so make sure slave_parallel_workers is set higher than 0.
MariaDB users should also check optimistic mode introduced in version 10.1.3 as it also may give you better results.
GTID
MariaDB comes with its own implementation of GTID. MariaDB’s sequence consists of a domain, server, and transaction. Domains allow multi-source replication with distinct ID. Different domain ID’s can be used to replicate the portion of data out-of-order (in parallel). As long it’s okayish for your application this can reduce replication latency.
The similar technique applies to MySQL 5.7 which can also use the multisource master and independent replication channels.
Compression
CPU power is getting less expensive over time, so using it for binlog compression could be a good option for many database environments. The slave_compressed_protocol parameter tells MySQL to use compression if both master and slave support it. By default, this parameter is disabled.
Starting from MariaDB 10.2.3, selected events in the binary log can be optionally compressed, to save the network transfers.
Replication formats
MySQL offers several replication modes. Choosing the right replication format helps to minimize the time to pass data between the cluster nodes.
Multimaster Replication For High Availability
Some applications can not afford to operate on outdated data.
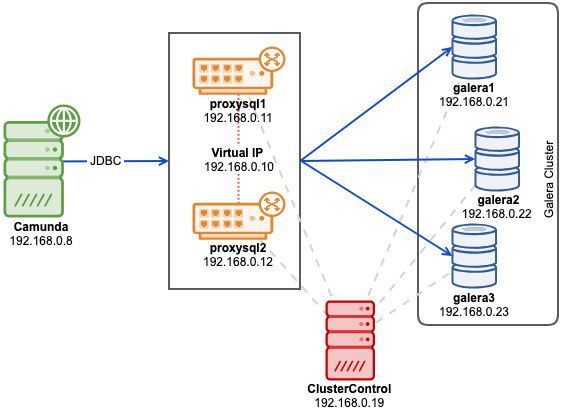
In such cases, you may want to enforce consistency across the nodes with synchronous replication. Keeping data synchronous requires an additional plugin, and for some, the best solution on the market for that is Galera Cluster.
Galera cluster comes with wsrep API which is responsible of transmitting transactions to all nodes and executing them according to a cluster-wide ordering. This will block the execution of subsequent queries until the node has applied all write-sets from its applier queue. While it’s a good solution for consistency, you may hit some architectural limitations. The common latency issues can be related to:
- The slowest node in the cluster
- Horizontal scaling and write operations
- Geolocated clusters
- High Ping
- Transaction size
The slowest node in the cluster
By design, the write performance of the cluster cannot be higher than the performance of the slowest node in the cluster. Start your cluster review by checking the machine resources and verify the configuration files to make sure they all run on the same performance settings.
Parallelization
Parallel threads do not guarantee better performance, but it may speed up the synchronization of new nodes with the cluster. The status wsrep_cert_deps_distance tells us the possible degree of parallelization. It is the value of the average distance between the highest and lowest seqno values that can be possibly applied in parallel. You can use the wsrep_cert_deps_distance status variable to determine the maximum number of slave threads possible.
Horizontal scaling
By adding more nodes in the cluster, we have fewer points that could fail; however, the information needs to go across multi-instances until it’s committed, which multiplies the response times. If you need scalable writes, consider an architecture based on sharding. A good solution can be a Spider storage engine.
In some cases, to reduce information shared across the cluster nodes, you can consider having one writer at a time. It’s relatively easy to implement while using a load balancer. When you do this manually make sure you have a procedure to change DNS value when your writer node goes down.
Geolocated clusters
Although Galera Cluster is synchronous, it is possible to deploy a Galera Cluster across data centers. Synchronous replication like MySQL Cluster (NDB) implements a two-phase commit, where messages are sent to all nodes in a cluster in a 'prepare' phase, and another set of messages are sent in a 'commit' phase. This approach is usually not suitable for geographically disparate nodes, because of the latencies in sending messages between nodes.
High Ping
Galera Cluster with the default settings does not handle well high network latency. If you have a network with a node that shows a high ping time, consider changing evs.send_window and evs.user_send_window parameters. These variables define the maximum number of data packets in replication at a time. For WAN setups, the variable can be set to a considerably higher value than the default value of 2. It’s common to set it to 512. These parameters are part of wsrep_provider_options.
--wsrep_provider_options="evs.send_window=512;evs.user_send_window=512"Transaction size
One of the things you need to consider while running Galera Cluster is the size of the transaction. Finding the balance between the transaction size, performance and Galera certification process is something you have to estimate in your application. You can find more information about that in the article How to Improve Performance of Galera Cluster for MySQL or MariaDB by Ashraf Sharif.
Load Balancer Causal Consistency Reads
Even with the minimized risk of data latency issues, standard MySQL asynchronous replication cannot guarantee consistency. It is still possible that the data is yet not replicated to slave while your application is reading it from there. Synchronous replication can solve this problem, but it has architecture limitations and may not fit your application requirements (e.g., intensive bulk writes). So how to overcome it?
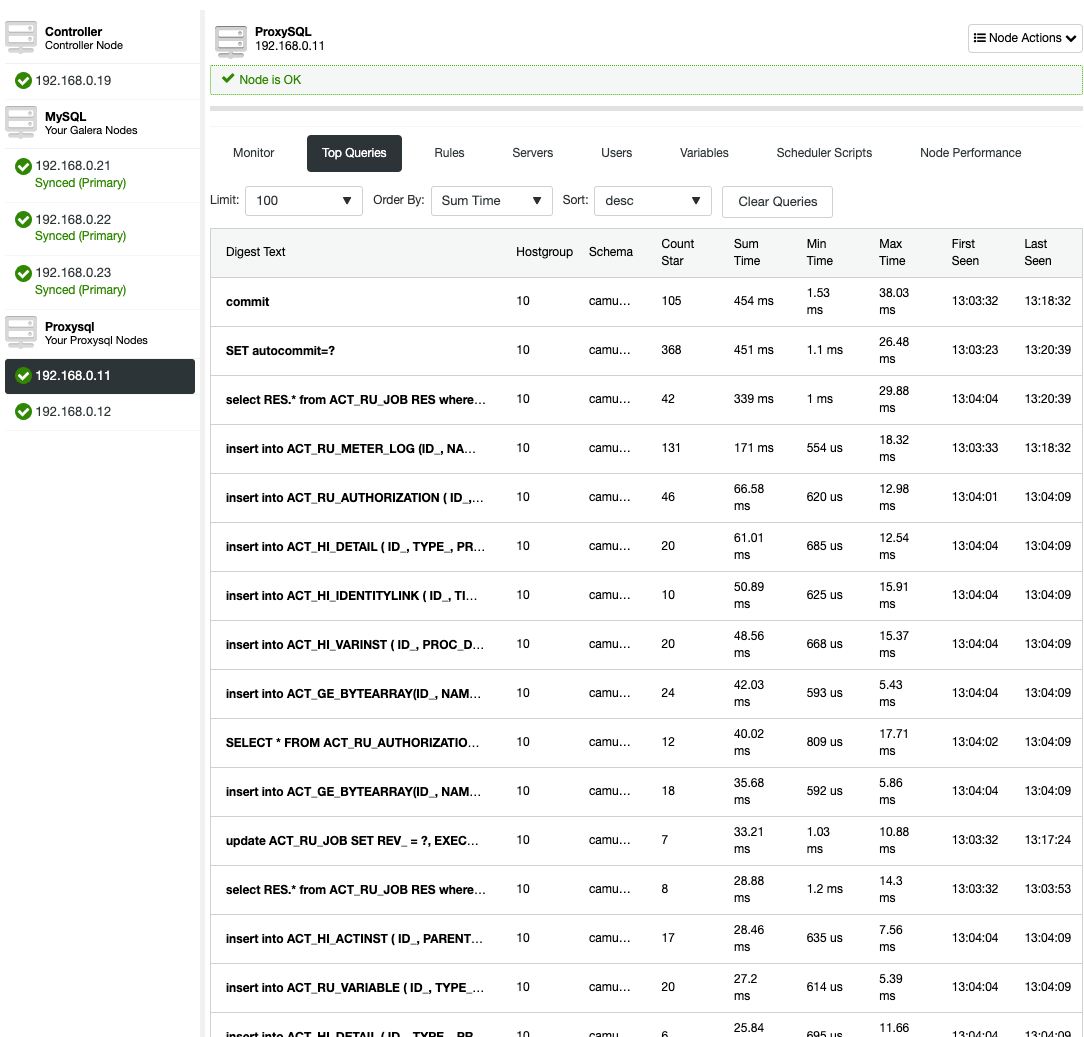
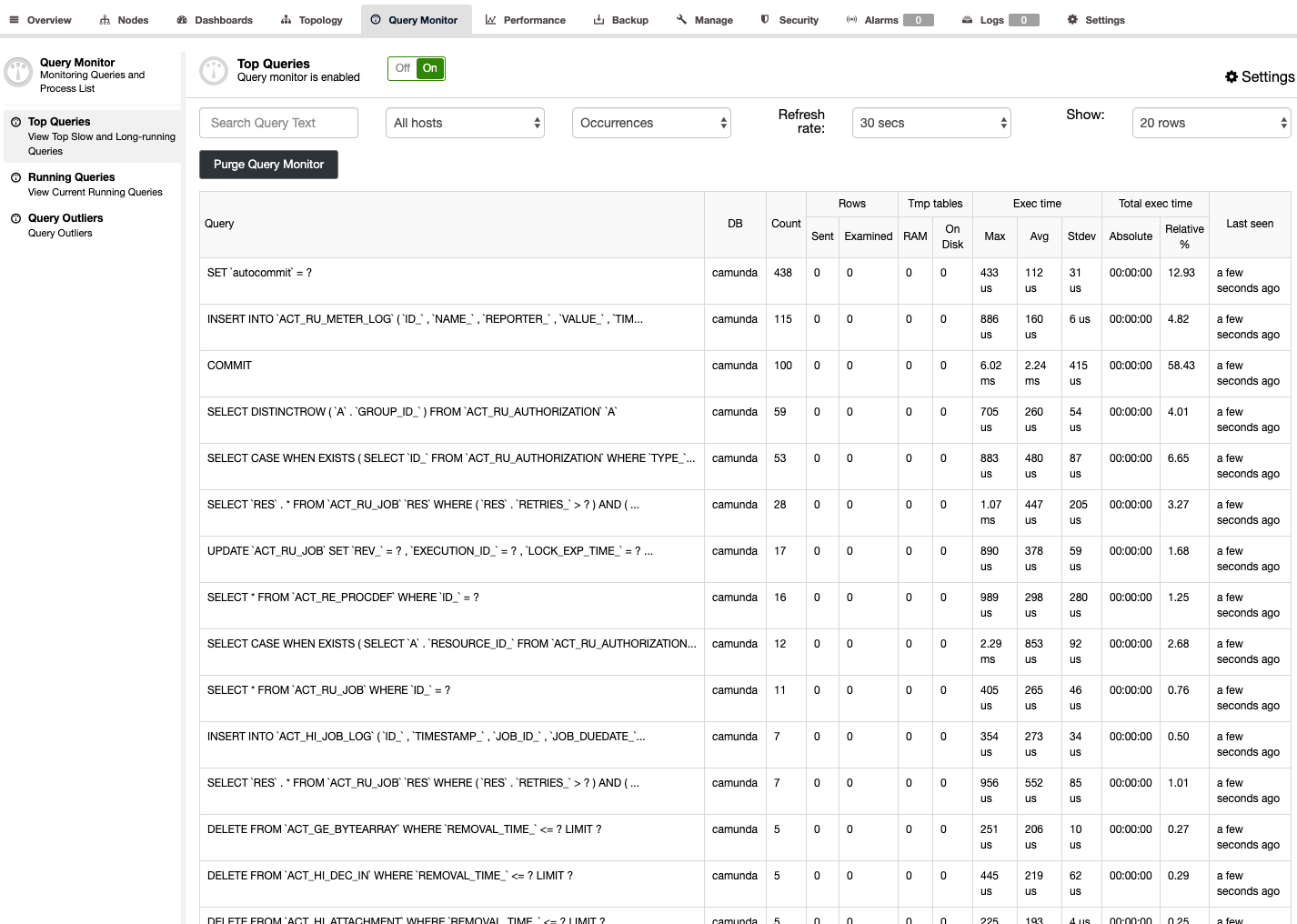
The first step to avoid stale data reading is to make the application aware of replication delay. It is usually programmed in application code. Fortunately, there are modern database load balancers with the support of adaptive query routing based on GTID tracking. The most popular are ProxySQL and Maxscale.
ProxySQL 2.0
ProxySQL Binlog Reader allows ProxySQL to know in real time which GTID has been executed on every MySQL server, slaves and master itself. Thanks to this, when a client executes a reads that needs to provide causal consistency reads, ProxySQL immediately knows on which server the query can be executed. If for whatever reason the writes were not executed on any slave yet, ProxySQL will know that the writer was executed on master and send the read there.
Maxscale 2.3
MariaDB introduced casual reads in Maxscale 2.3.0. The way it works it’s similar to ProxySQL 2.0. Basically when causal_reads are enabled, any subsequent reads performed on slave servers will be done in a manner that prevents replication lag from affecting the results. If the slave has not caught up to the master within the configured time, the query will be retried on the master.