Microsoft Azure is known to many as an alternative public cloud platform to Amazon AWS. It's not easy to directly compare these two giant companies. Microsoft's cloud business -- dubbed commercial cloud -- includes everything from Azure to Office 365 enterprise subscriptions to Dynamics 365 to LinkedIn services. After LinkedIn was acquired by Microsoft it began moving its infrastructure to Azure. While moving LinkedIn to Azure could take some time, it demonstrates Microsoft Azure’s capabilities and ability to handle millions of transactions. Microsoft's strong enterprise heritage, software stack, and data center tools offer both familiarity and a hybrid approach to cloud deployments.
Microsoft Azure is built as an Infrastructure as a Service (IaaS) as well as a Platform as a Service (PaaS). The Azure Virtual machine offers per-second billing and it's currently a multi-tenant compute. It has, however, recently previewed its new offering which allows virtual machines to run on single-tenant physical servers. The offering is called Azure Dedicated Hosts.
Azure also offers specialized large instances (such as for SAP HANA). There are multitenant blocks, file storage, and many other additional IaaS and PaaS capabilities. These include object storage (Azure Blob Storage), a CDN, a Docker-based container service (Azure Container Service), a batch computing service (Azure Batch), and event-driven “serverless computing” (Azure Functions). The Azure Marketplace offers third-party software and services. Colocation needs are met via partner exchanges (Azure ExpressRoute) offered from partners like Equinix and CoreSite.
With all of these offerings Microsoft Azure has stepped up its game to play a vital role in the public cloud market. The PaaS infrastructure offered to its consumers has garnered a lot of trust and many are moving their own infrastructure or private cloud to Microsoft Azure's public cloud infrastructure. This is especially advantageous for consumers who need integration with other Windows Services, such as Visual Studio.
So what’s different between Azure and the other clouds we have looked at in this series? Microsoft has focused heavily on AI, analytics, and the Internet of Things. AzureStack is another “cloud-meets-data center” effort that has been a real differentiator in the market.
Microsoft Azure Migration Pros & Cons
There are several things you should consider when moving your legacy applications or infrastructure to Microsoft Azure.
Strengths
- Enterprises that are strategically committed to Microsoft technology generally choose Azure as their primary IaaS+PaaS provider. The integrated end-to-end experience for enterprises building .NET applications using Visual Studio (and related services) is unsurpassed. Microsoft is also leveraging its tremendous sales reach and ability to co-sell Azure with other Microsoft products and services in order to drive adoption.
- Azure provides a well-integrated approach to edge computing and Internet of Things (IoT), with offerings that reach from its hyperscale data center out through edge solutions such as AzureStack and Data Box Edge.
- Microsoft Azure’s capabilities have become increasingly innovative and open. 50% of the workloads are Linux-based alongside numerous open-source application stacks. Microsoft has a unique vision for the future that involves bringing in technology partners through native, first-party offerings such as those from VMware, NetApp, Red Hat, Cray and Databricks.
Cautions
- Microsoft Azure’s reliability issues continue to be a challenge for customers, largely as a result of Azure’s growing pains. Since September 2018, Azure has had multiple service-impacting incidents, including significant outages involving Azure Active Directory. These outages leave customers with no ability to mitigate the downtime.
- Gartner clients often experience challenges with executing on-time implementations within budget. This comes from Microsoft often providing unreasonably high expectations for customers. Much of this stems from the Microsoft’s field sales teams being “encouraged” to appropriately position and sell Azure within its customer base.
- Enterprises frequently lament the quality of Microsoft technical support (along with the increasing cost of support) and field solution architects. This negatively impacts customer satisfaction, and slows Azure adoption and therefore customer spending.
Microsoft may not be your first choice as it has been seen as a “not-so-open-source-friendly” tech giant, but in fairness it has embraced a lot of activity and support within the Open Source world. Microsoft Azure offers fully-managed services to most of the top open source RDBMS database like PostgreSQL, MySQL, and MariaDB.
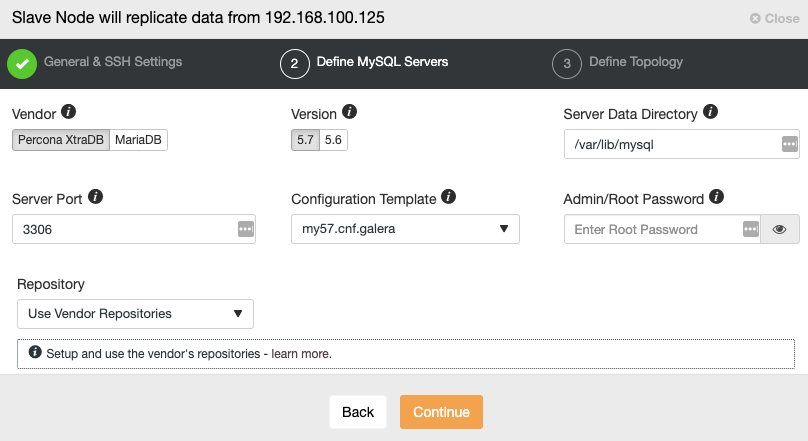
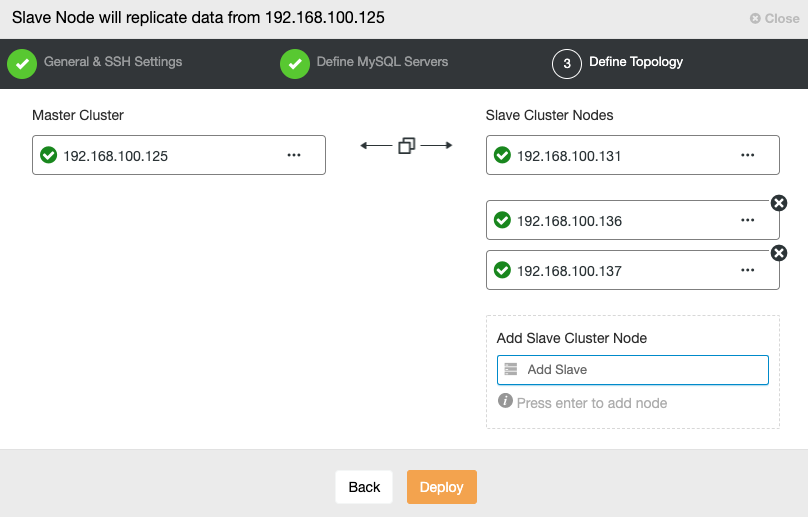
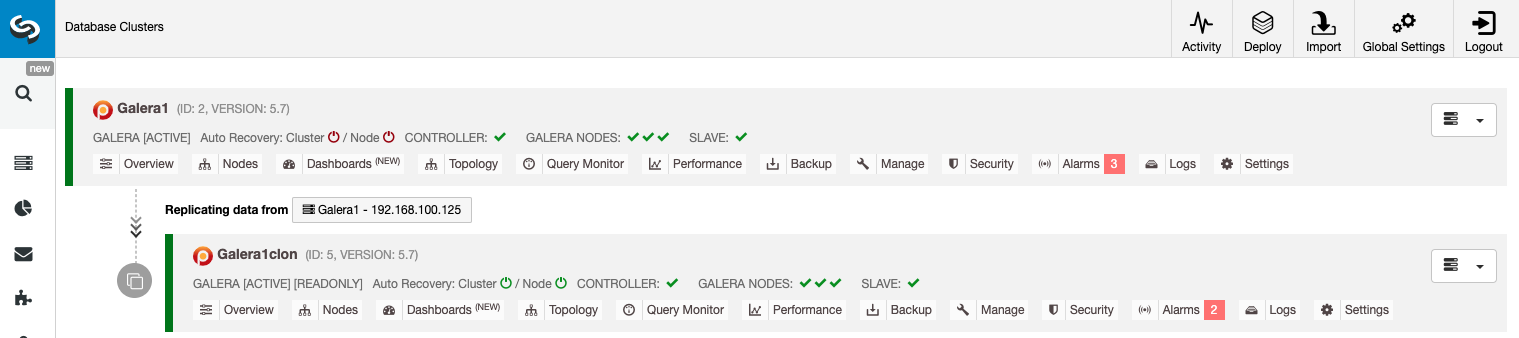
Galera Cluster (Percona, Codership, or MariaDB) variants, unfortunately, aren't supported by Azure. The only way you can deploy your Galera Cluster to Azure is by means of a Virtual Machine. You may also want to check their blog on using MariaDB Enterprise Cluster (which is based on Galera) on Azure.
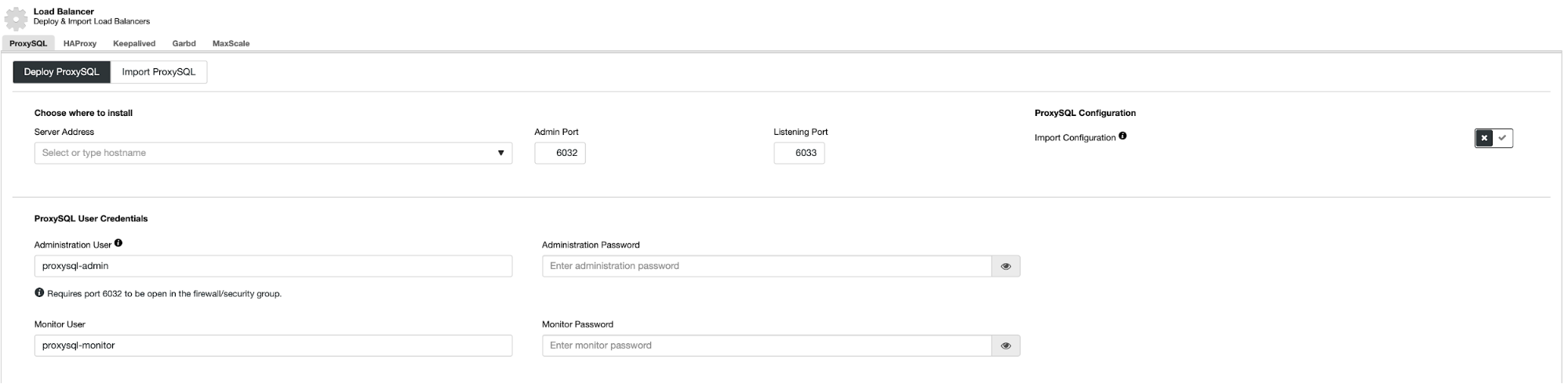
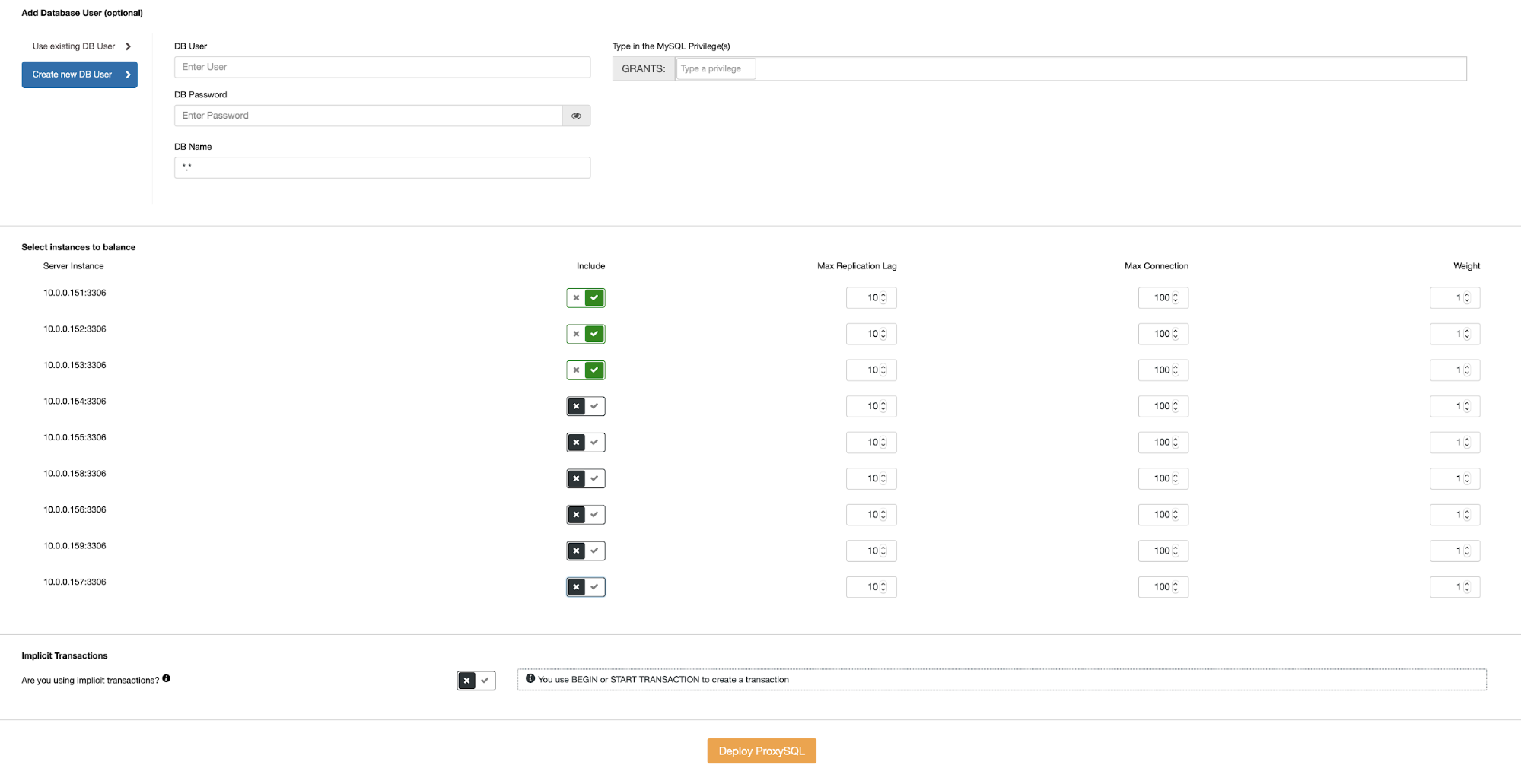
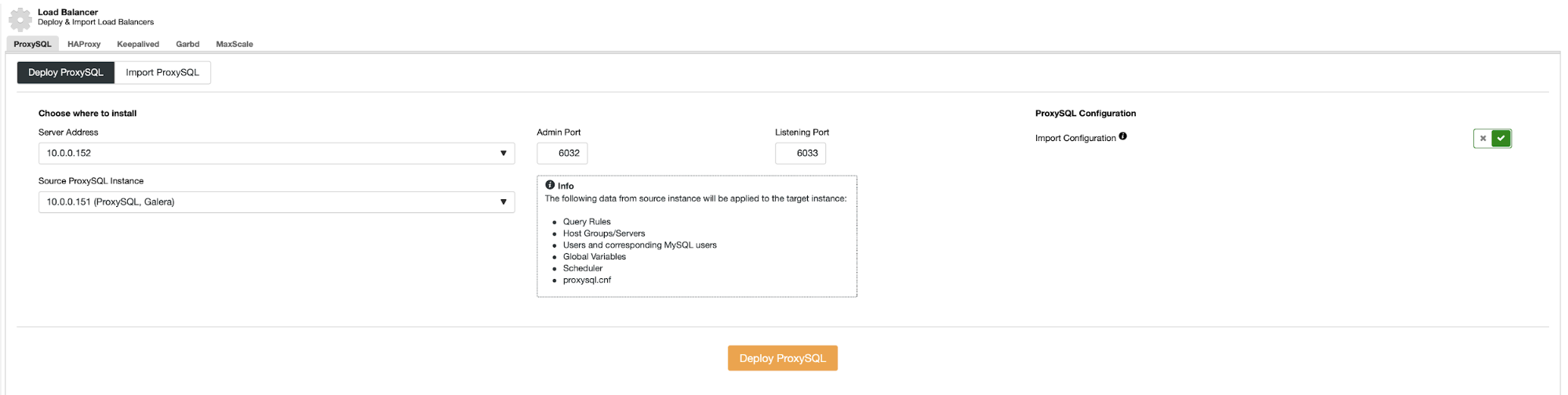
Azure's Virtual Machine
Virtual Machine is the equivalent offering for compute instances in GCP and AWS. An Azure Virtual Machine is an on-demand, high-performance computing server in the cloud and can be deployed in Azure using various methods. These might include the user interface within the Azure portal, using pre-configured images in the Azure marketplace, scripting through Azure PowerShell, deploying from a template that is defined by using a JSON file, or by deploying directly through Visual Studio.
Azure uses a deployment model called the Azure Resource Manager (ARM), which defines all resources that form part of your overall application solution, allowing you to deploy, update, or delete your solution in a single operation.
Resources may include the storage account, network configurations, and IP addresses. You may have heard the term “ARM templates”, which essentially means the JSON template which defines the different aspects of your solution which you are trying to deploy.
Azure Virtual Machines come in different types and sizes, with names beginning with A-series to N-series. Each VM type is built with specific workloads or performance needs in mind, including general purpose, compute optimized, storage optimized or memory optimized. You can also deploy less common types like GPU or high performance compute VMs.
Similar to other public cloud offerings, you can do the following in your virtual machine instances...
- Encrypt your disk on virtual machine. Although this does not come easily when compared to GCP and AWS. Encrypting your virtual machine requires a more manual approach. It requires you to complete the Azure Disk Encryption prerequisites. Since Galera does not support Windows, we're only talking here about Linux-based images. Basically, it requires you to have dm-crypt and vfat modules present in the system. Once you get that piece right, then you can encrypt the VM using the Azure CLI. You can check out how to Enable Azure Disk Encryption for Linux IaaS VMs to see how to do it. Encrypting your disk is very important, especially if your company or organization requires that your Galera Cluster data must follow the standards mandated by laws and regulations such as PCI DSS or GDPR.
- Creating a snapshot. You can create a snapshot either using the Azure CLI or through the portal. Check their manual on how to do it.
- Use auto scaling or Virtual Machine Scale Sets if you require horizontal scaling. Check out the overview of autoscaling in Azure or the overview of virtual machine scale sets.
- Multi Zone Deployment. Deploy your virtual machine instances into different availability zones to avoid single-point of failure.
You can also create (or get information from) your virtual machines in different ways. You can use the Azure portal, Azure PowerShell, REST APIs, Client SDKs, or with the Azure CLI. Virtual machines in the Azure virtual network can also easily be connected to your organization’s network and treated as an extended datacenter.
Microsoft Azure Pricing
Just like other public cloud providers, Microsoft Azure also offers a free tier with some free services. It also offers pay-as-you-go options and reserved instances to choose from. Pay-as-you-go starts at $0.008/hour - $0.126/hour.

For reserved instances, the longer you commit and contract with Azure, the more you save on the cost. Microsoft Azure claims to help subscribers save up to 72% of their billing costs compared to its pay-as-you-go model when subscribers sign up for a one to three year term for a Windows or Linux Virtual Machine. Microsoft also offers added flexibility in the sense that if your business needs change, you can cancel your Azure RI subscription at any time and return the remaining unused RI to Microsoft as an early termination fee.
Let's checkout it's pricing in comparison between GCP, AWS EC2, and an Azure Virtual Machine. This is based on us-east1 region and we will compare the price ranges for the compute instances required to run your Galera Cluster.
Machine/ | Google | AWS EC2 | Microsoft |
Shared | f1-micro G1-small Prices starts at $0.006 - $0.019 hourly | t2.nano – t3a.2xlarge Price starts at $0.0058 - $0.3328 hourly | B-Series Price starts at $0.0052 - $0.832 hourly |
Standard | n1-standard-1 – n1-standard-96 Prices starts at $0.034 - $3.193 hourly | m4.large – m4.16xlarge m5.large – m5d.metal Prices starts at $0.1 - $5.424 hourly | Av2 Standard, D2-64 v3 latest generation, D2s-64s v3 latest generation, D1-5 v2, DS1-S5 v2, DC-series Price starts at $0.043 - $3.072 hourly |
High Memory/ Memory Optimized | n1-highmem-2 – n1-highmem-96 n1-megamem-96 n1-ultramem-40 – n1-ultramem-160 Prices starts at $0.083 - $17.651 hourly | r4.large – r4.16xlarge x1.16xlarge – x1.32xlarge x1e.xlarge – x1e.32xlarge Prices starts at $0.133 - $26.688 hourly | D2a – D64a v3, D2as – D64as v3, E2-64 v3 latest generation, E2a – E64a v3, E2as – E64as v3, E2s-64s v3 latest generation, D11-15 v2, DS11-S15 v2, M-series, Mv2-series, Instances, Extreme Memory Optimized Price starts at $0.043 - $44.62 hourly |
High CPU/Storage Optimized | n1-highcpu-2 – n1-highcpu-32 Prices starts at $0.05 - $2.383 hourly | h1.2xlarge – h1.16xlarge i3.large – i3.metal I3en.large - i3en.metal d2.xlarge – d2.8xlarge Prices starts at $0.156 - $10.848 hourly | Fsv2-series, F-series, Fs-Series Price starts at $0.0497 - $3.045 hourly |
Data Encryption on Microsoft Azure
Microsoft Azure does not offer encryption support directly for Galera Cluster (or vice-versa). There are, however, ways you can encrypt data either at-rest or in-transit.
Encryption in-transit is a mechanism for protecting data when it's transmitted across networks. With Azure Storage, you can secure data by using:
- Transport-level encryption, such as HTTPS, when you transfer data into or out of Azure Storage.
- Wire encryption, such as SMB 3.0 encryption, for Azure file shares.
- Client-side encryption, to encrypt the data before it's transferred into Storage and to decrypt the data after it is transferred out of Storage.
Microsoft uses encryption to protect customer data when it’s in-transit between customers realm and Microsoft cloud services. More specifically, Transport Layer Security (TLS) is the protocol that Microsoft’s data centers will use to negotiate with client systems that are connected to Microsoft cloud services.
Perfect Forward Secrecy (PFS) is also employed so that each connection between customers’ client systems and Microsoft’s cloud services use unique keys. Connections to Microsoft cloud services also take advantage of RSA based 2,048-bit encryption key lengths.
Encryption At-Rest
For many organizations, data encryption at-rest is a mandatory step towards achieving data privacy, compliance, and data sovereignty. Three Azure features provide encryption of data at-rest:
- Storage Service Encryption is always enabled and automatically encrypts storage service data when writing it to Azure Storage. If your application logic requires your MySQL Galera Cluster database to store valuable data, then storing to Azure Storage can be an option.
- Client-side encryption also provides the feature of encryption at-rest.
- Azure Disk Encryption enables you to encrypt the OS disks and data disks that an IaaS virtual machine uses. Azure Disk Encryption also supports enabling encryption on Linux VMs that are configured with disk striping (RAID) by using mdadm, and by enabling encryption on Linux VMs by using LVM for data disks
Galera Cluster Multi-AZ/Multi-Region/Multi-Cloud Deployments with GCP
Similar to AWS and GCP, Microsoft Azure does not offer direct support for deploying a Galera Cluster onto a Multi-AZ/-Region/-Cloud. You can, however, deploy your nodes manually as well as creating scripts using PowerShell or Azure CLI to do this for you. Alternatively, when you provision your Virtual Machine instance you can place your nodes in different availability zones. Microsoft Azure also offers another type of redundancy, aside from having its availability zone, which is called Virtual Machine Scale Sets. You can check the differences between virtual machine and scale sets.
Galera Cluster High Availability, Scalability, and Redundancy on Azure
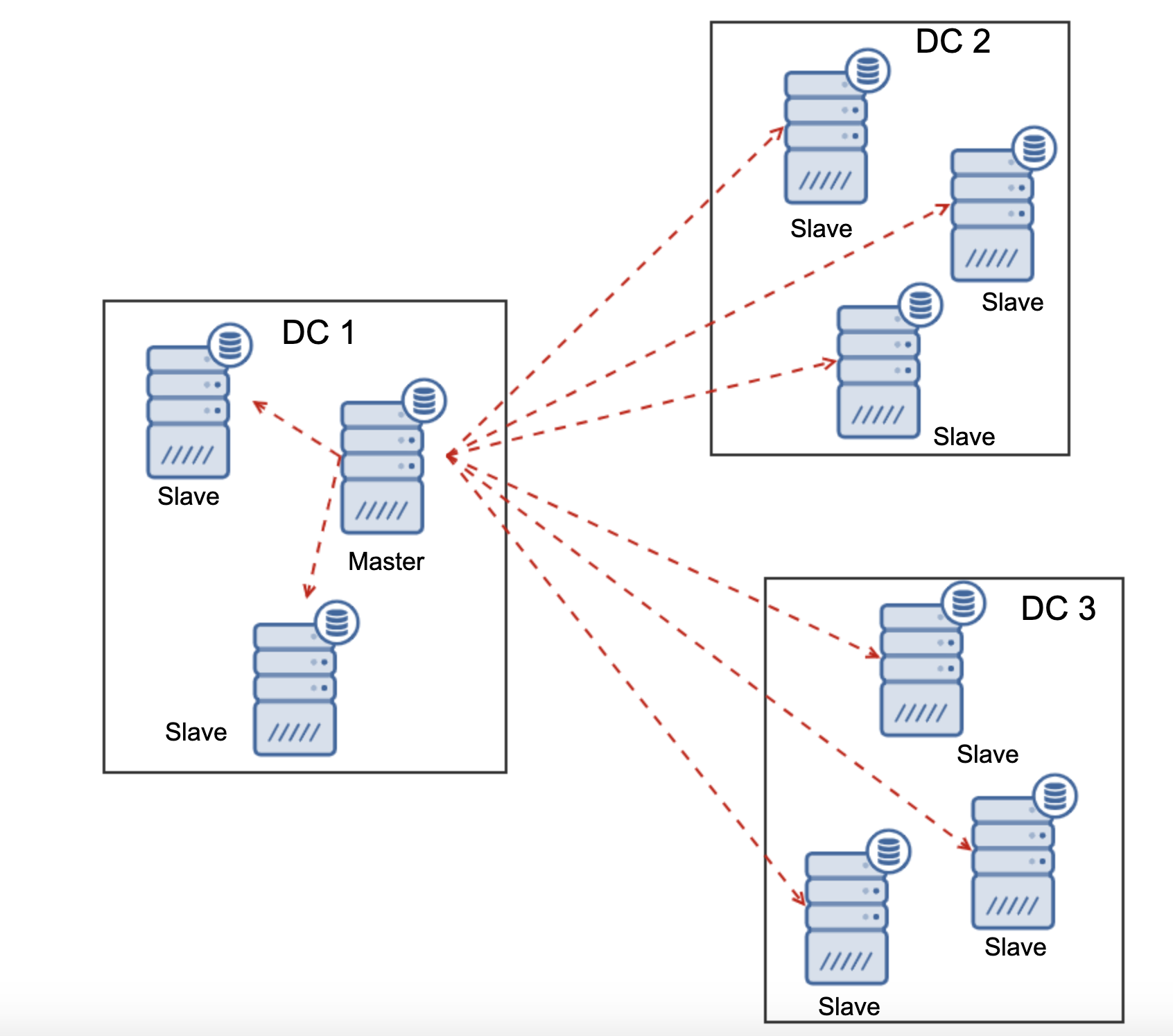
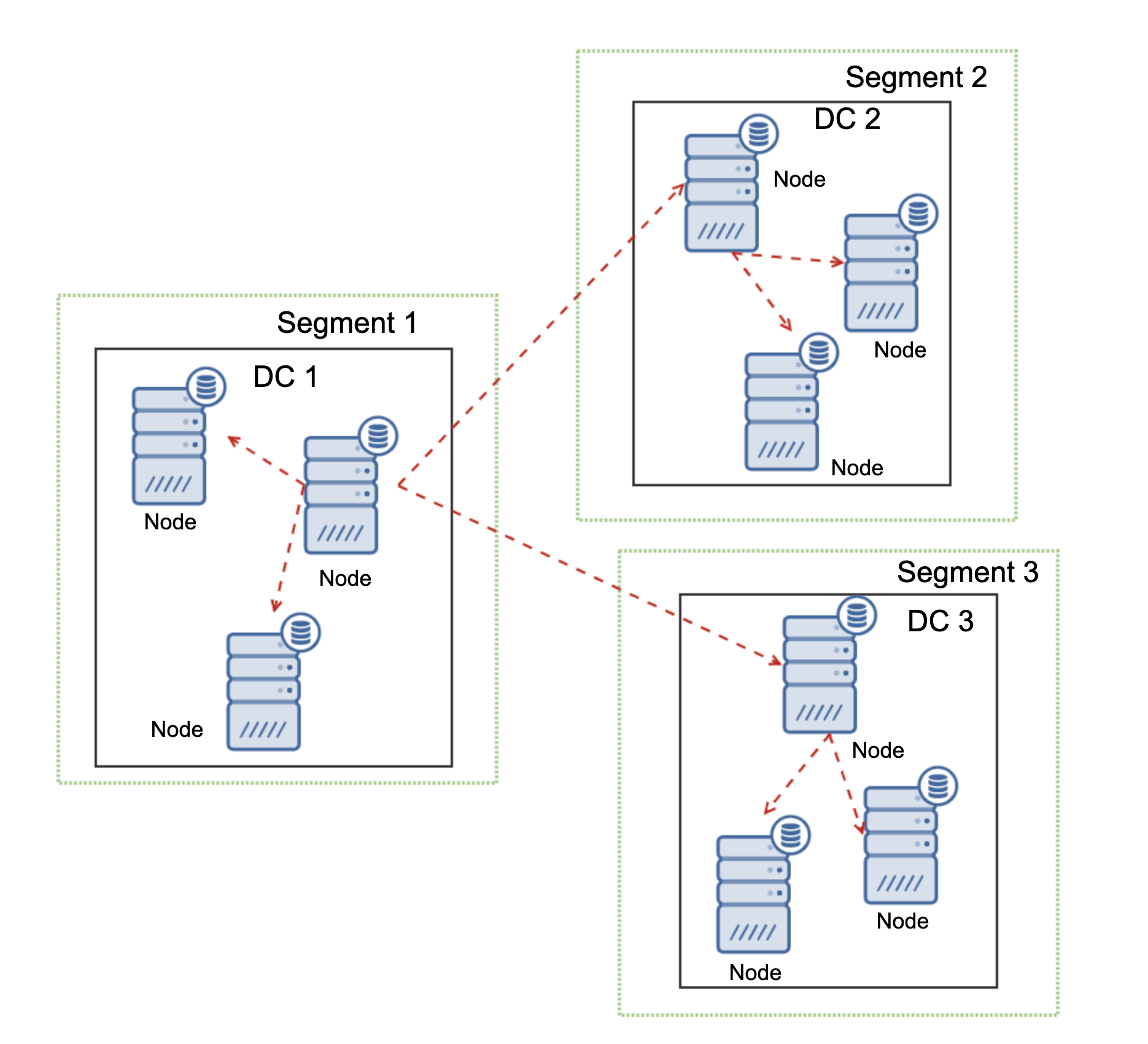
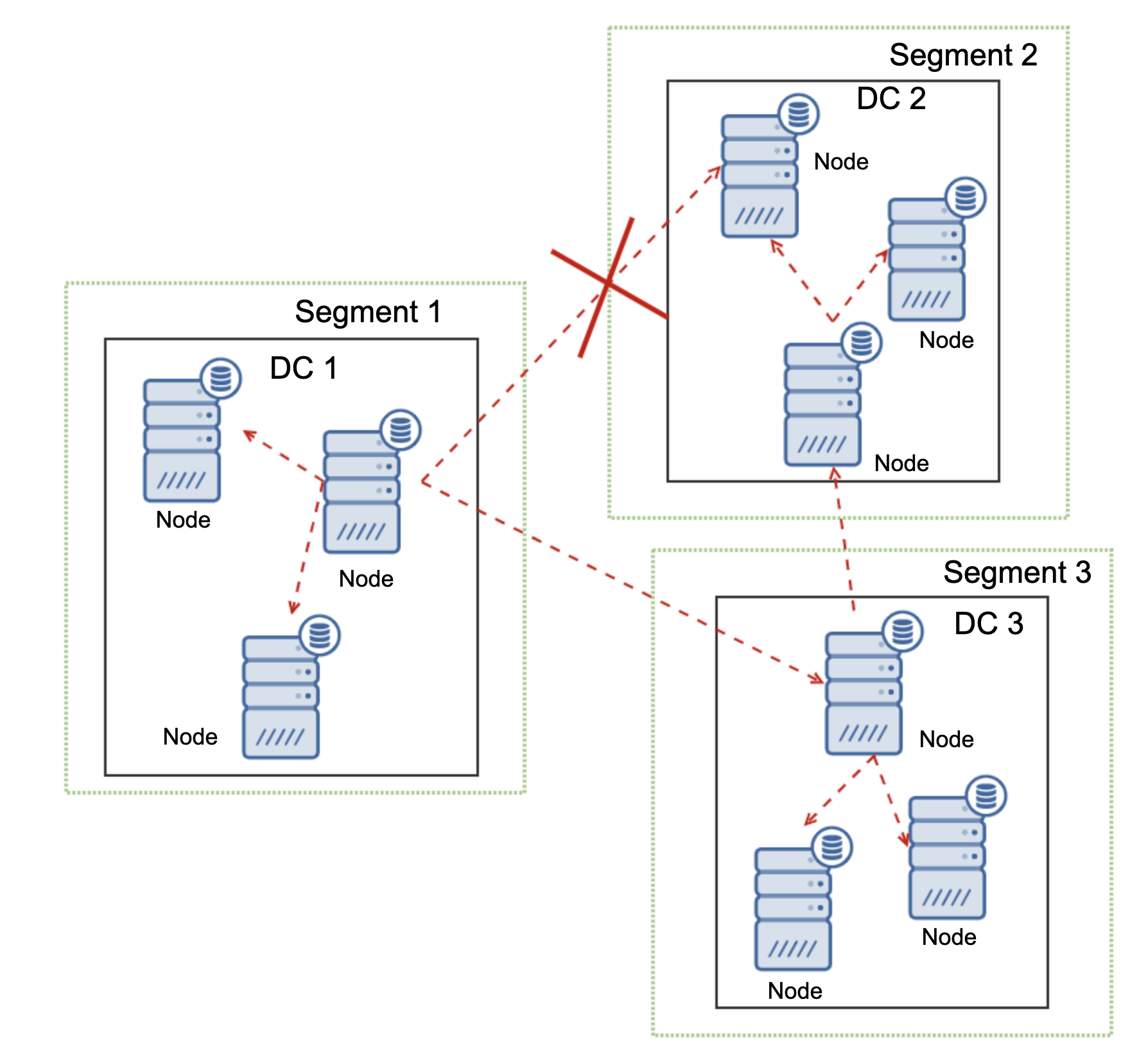
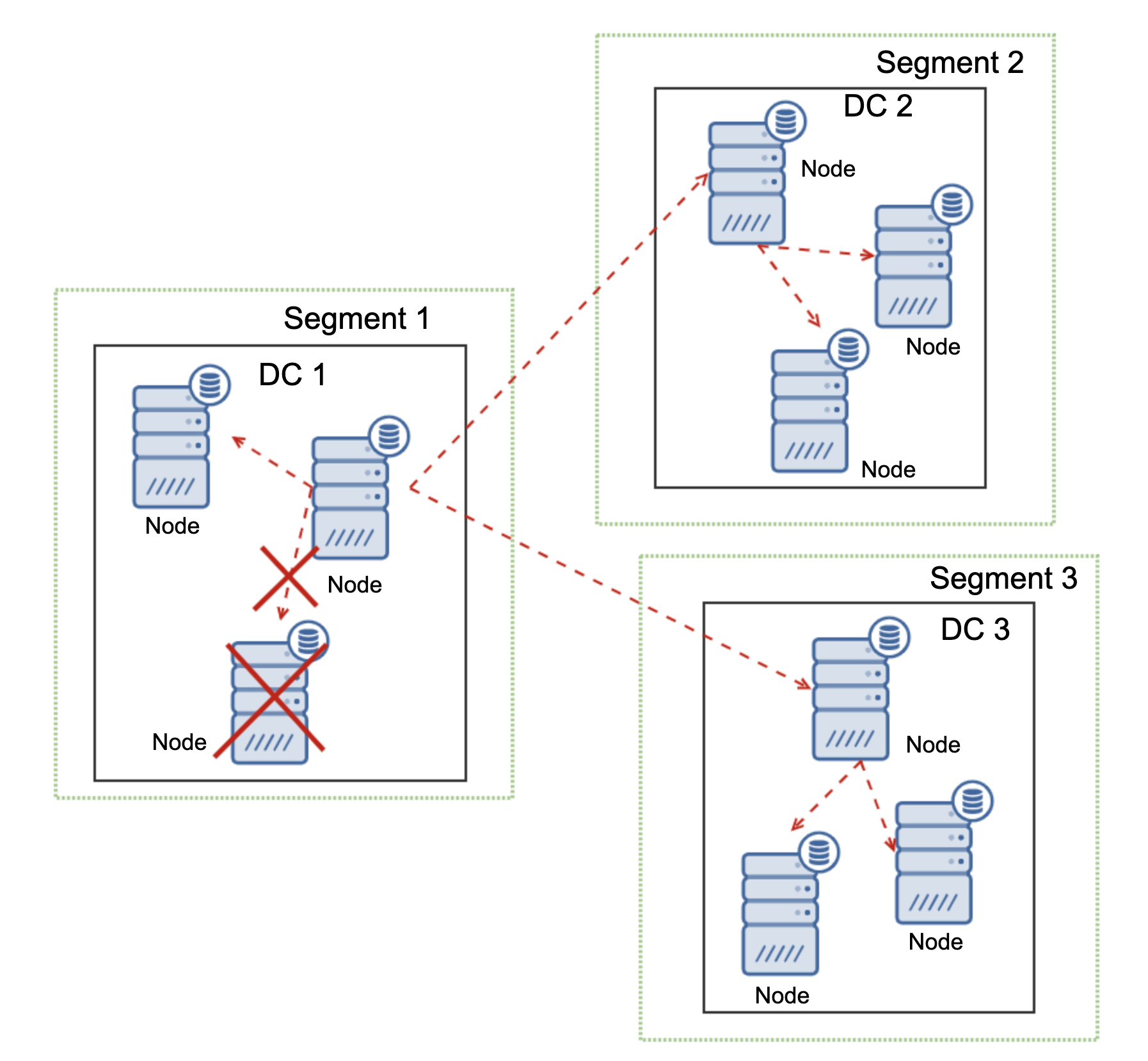
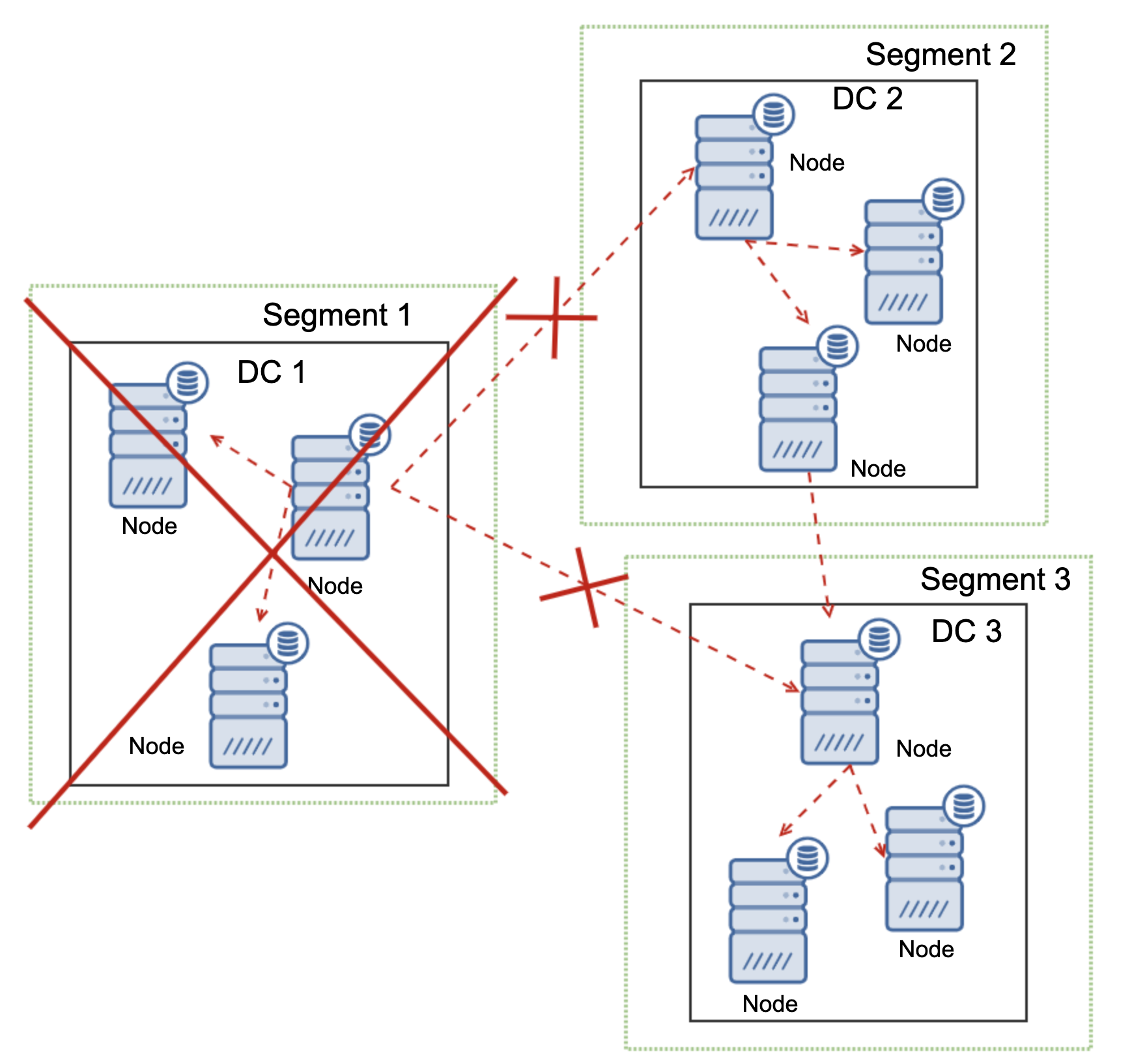
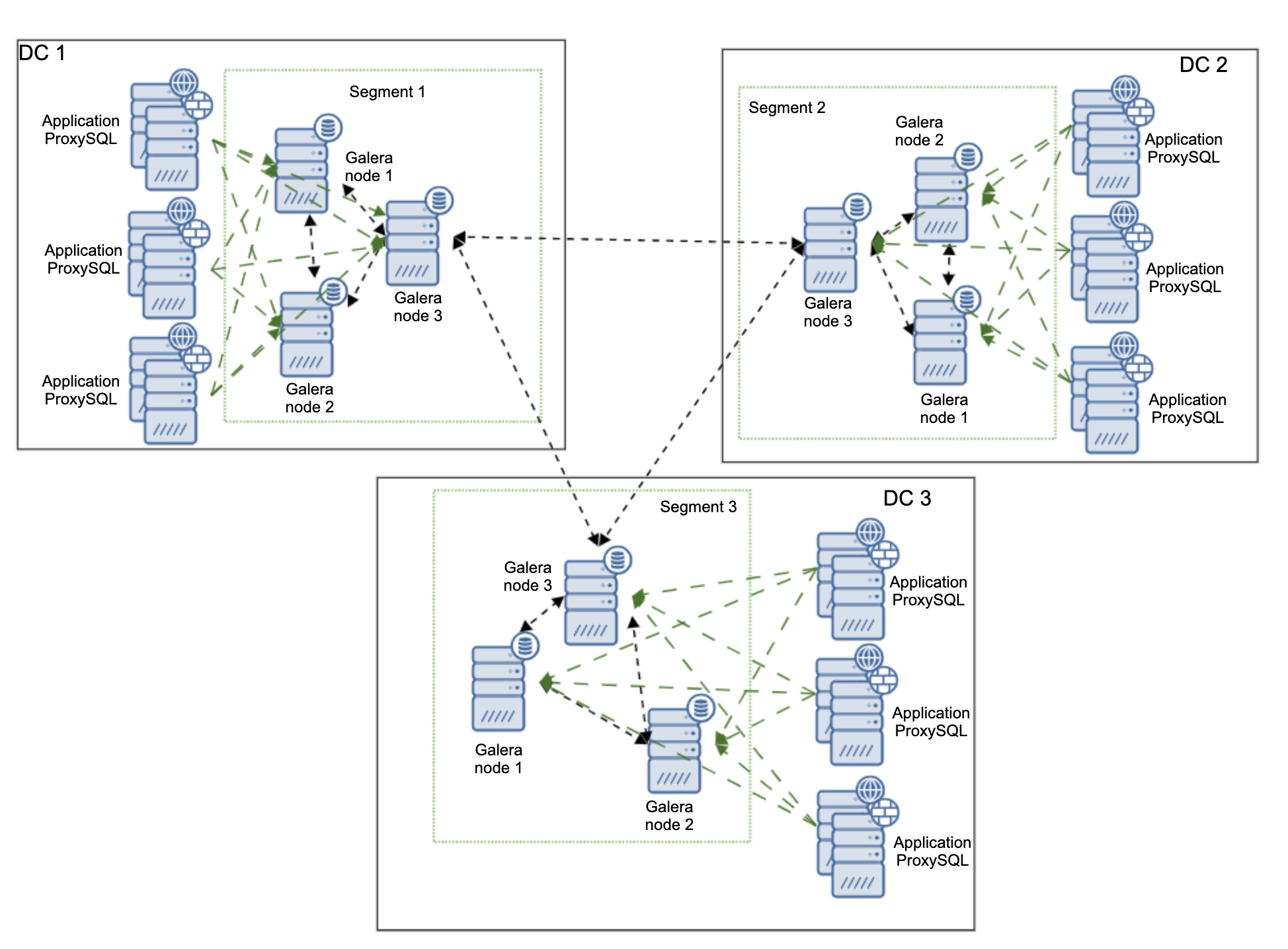
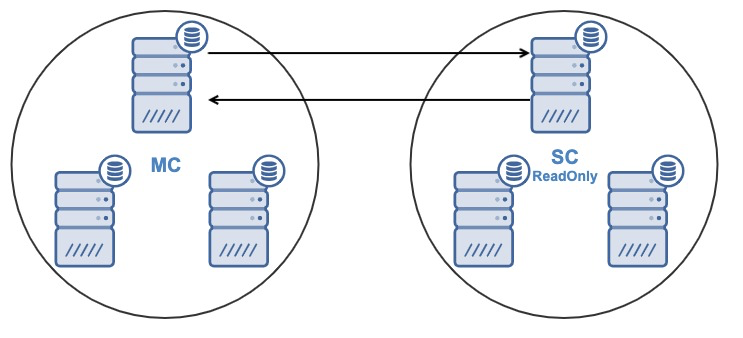
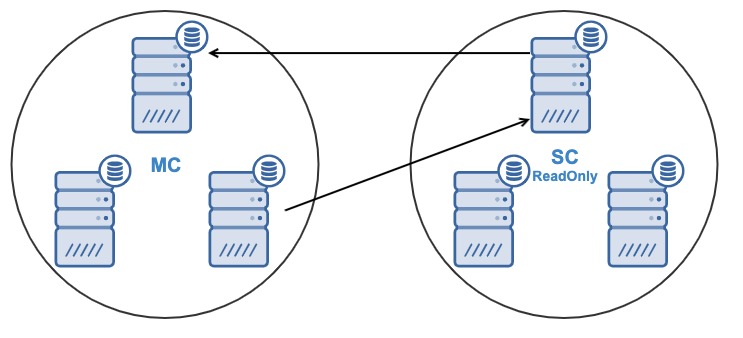
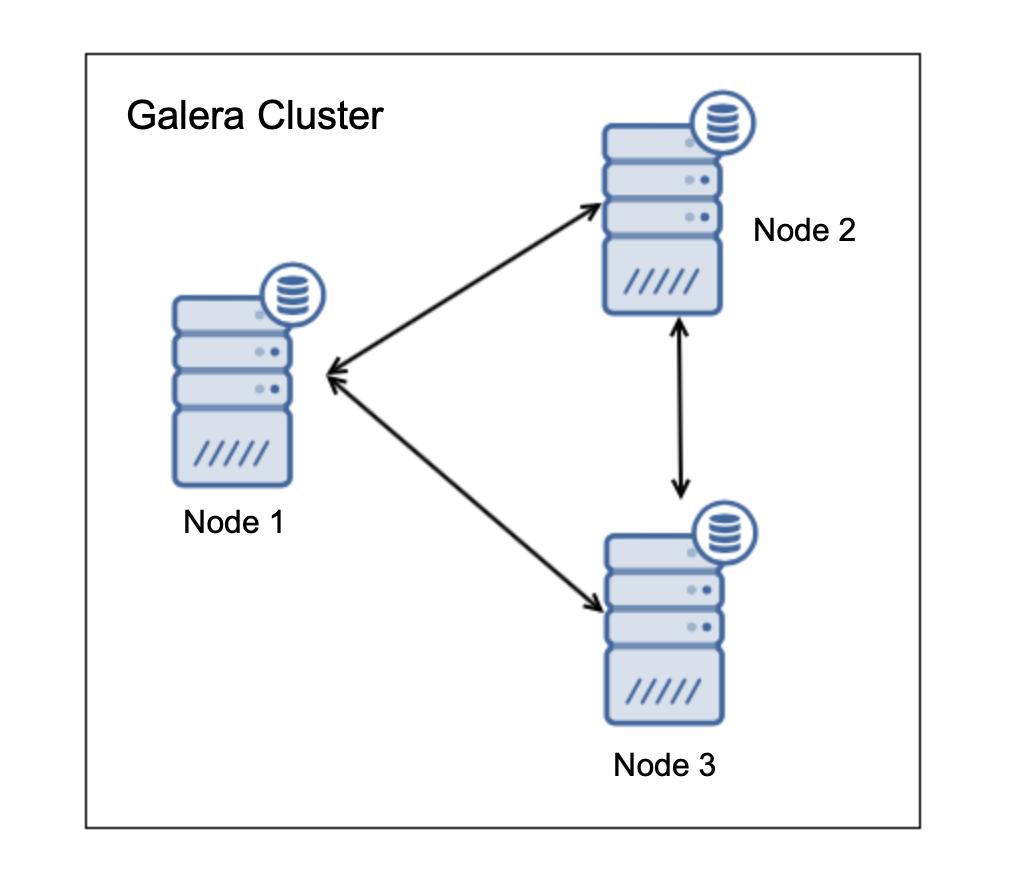
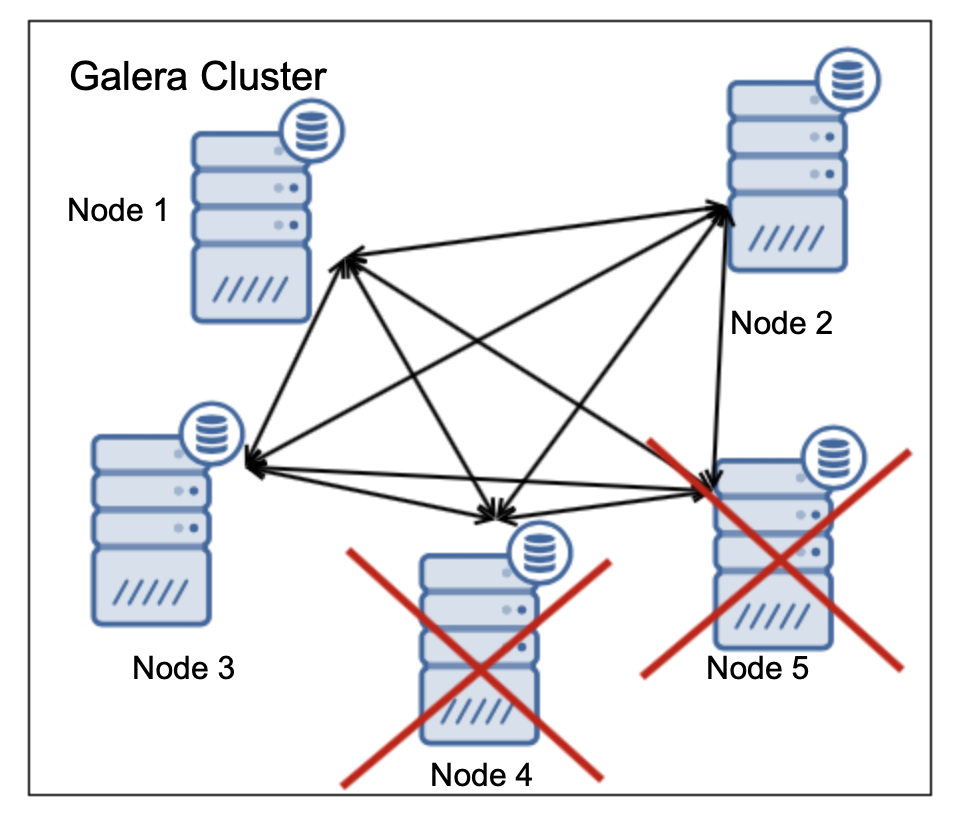
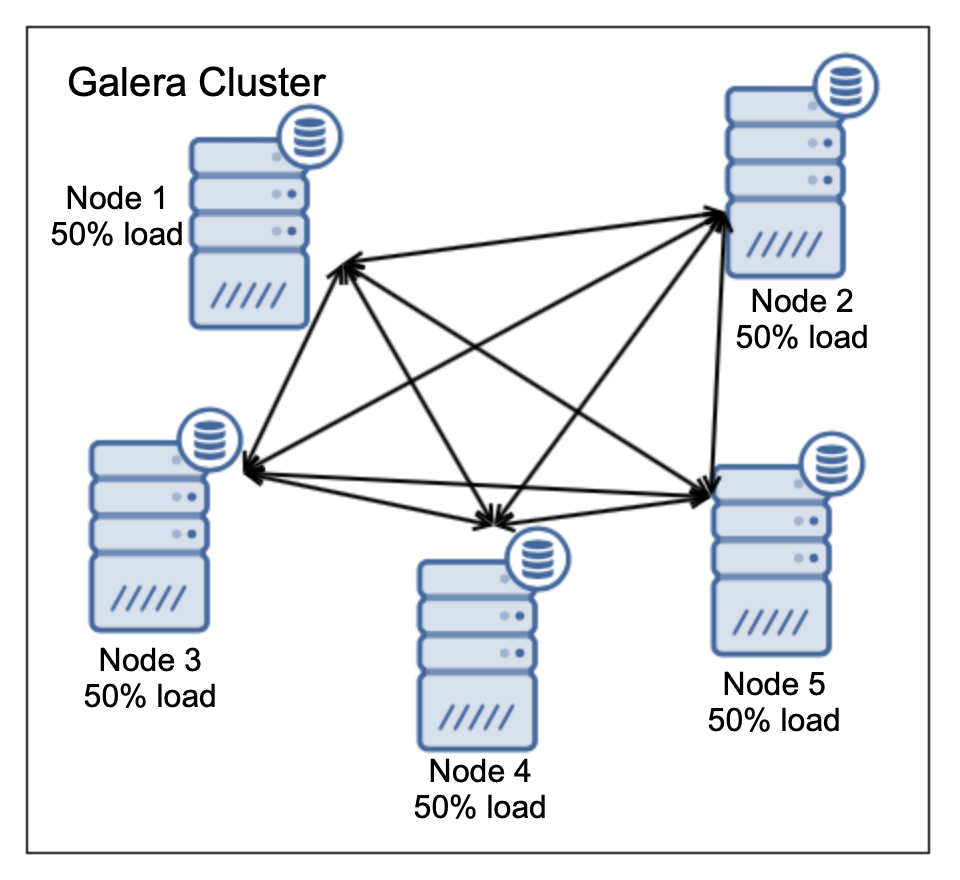
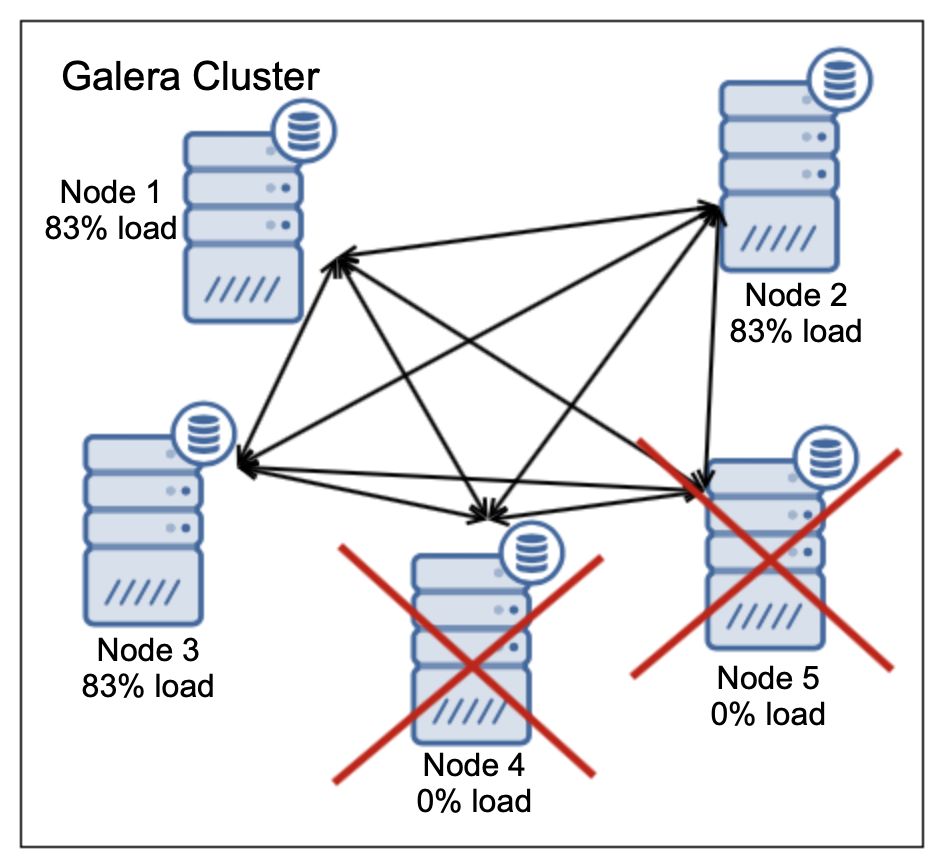
One of the primary reasons for using a Galera node cluster is for high-availability, redundancy, and for its ability to scale. If you are serving traffic globally, it's best that you cater your traffic by region. You should ensure your architectural design includes geo-distribution of your database nodes. In order to achieve this, multi-AZ, multi-region, or multi-cloud/multi-datacenter deployments are recommended. This prevents the cluster from going down as well as a malfunction due to lack of quorum.
As mentioned earlier, Microsoft Azure has an auto scaling solution which can be leveraged using scale sets. This allows you to autoscale a node when a certain threshold has been met (based on what you are monitoring). This depends on which health status items you are monitoring before it then vertically scales. You can check out their tutorial on this topic here.
For multi-region or multi-cloud deployments, Galera has its own parameter called gmcast.segment for which can be set upon server start. This parameter is designed to optimize the communication between the Galera nodes and minimize the amount of traffic sent between network segments. This includes writeset relaying and IST and SST donor selection. This type of setup allows you to deploy multiple nodes in different regions. Aside from that, you can also deploy your Galera nodes on a different cloud vendors routing from GCP, AWS, Microsoft Azure, or within an on-premise setup.
We recommend you to check out our blog Multiple Data Center Setups Using Galera Cluster for MySQL or MariaDB and Zero Downtime Network Migration With MySQL Galera Cluster Using Relay Node to gather more information on how to implement these types of deployments.
Galera Cluster Database Performance on Microsoft Azure
The underlying host machines used by virtual machines in Azure are, in fact, very powerful. The newest VM's in Azure have already been equipped with network optimization modules. You can check this in your kernel info by running (e.g. in Ubuntu).
uname -r|grep azureNote: Make certain that your command has the "azure" string on it.
For Centos/RHEL, installing any Linux Integration Services (LIS) since version 4.2 contains network optimization. To learn more about this, visit the page on optimizing network throughput.
If your application is very sensitive to network latency, you might be interested in looking at the proximity placement group. It's currently in preview (and not yet recommended for production use) but this helps optimize your network throughput.
For the type of virtual machine you would consume, then this would depend on the requirement of your application traffic and resource demands. For queries that are high on memory consumption, you can start with Dv3. However, for memory-optimized, then start with the Ev3 series. For High CPU requirements, such as high-transactional database or gaming applications, then start with Fsv2 series.
Choosing the right storage and required IOPS for your database volume is a must. Generally, a SSD-based persistent disk is your ideal choice. Begin with Standard SSD which is cost-effective and offers consistent performance. This decision, however, might depend on if you need more IOPS in the long run. If this is the case, then you should go for Premium SSD storage.
We also recommend you to check and read our blog How to Improve Performance of Galera Cluster for MySQL or MariaDB to learn more about optimizing your Galera Cluster.
Database Backup for Galera Nodes on Azure
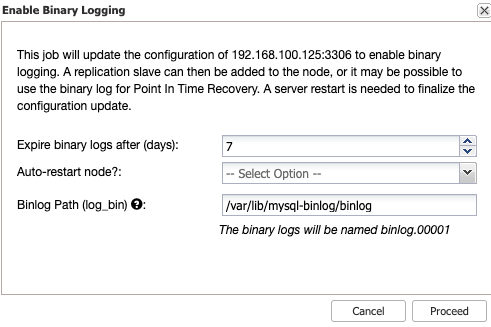
There's no existing naitve backup support for your MySQL Galera data in Azure, but you can take a snapshot. Microsoft Azure offers Azure VM Backup which takes a snapshot which can be scheduled and encrypted.
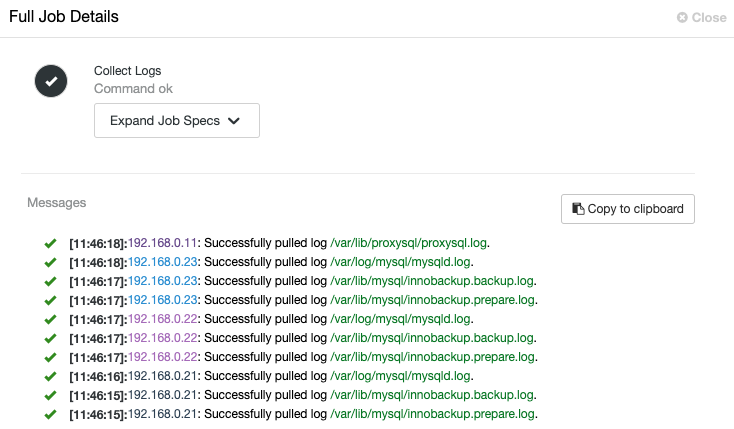
Alternatively, if you want to backup the data files from your Galera Cluster, you can also use external services like ClusterControl, use Percona Xtrabackup for your binary backup, or use mysqldump or mydumper for your logical backups. These tools provide backup copies for your mission-critical data and you can read this if you want to learn more.
Galera Cluster Monitoring on Azure
Microsoft Azure has its monitoring service named Azure Monitor. Azure Monitor maximizes the availability and performance of your applications by delivering a comprehensive solution for collecting, analyzing, and acting on telemetry from your cloud and on-premise environments. It helps you understand how your applications are performing and proactively identifies issues affecting them (and the resources they depend on). You can setup or create health alerts, get notified on advisories and alerts detected in the services you deployed.
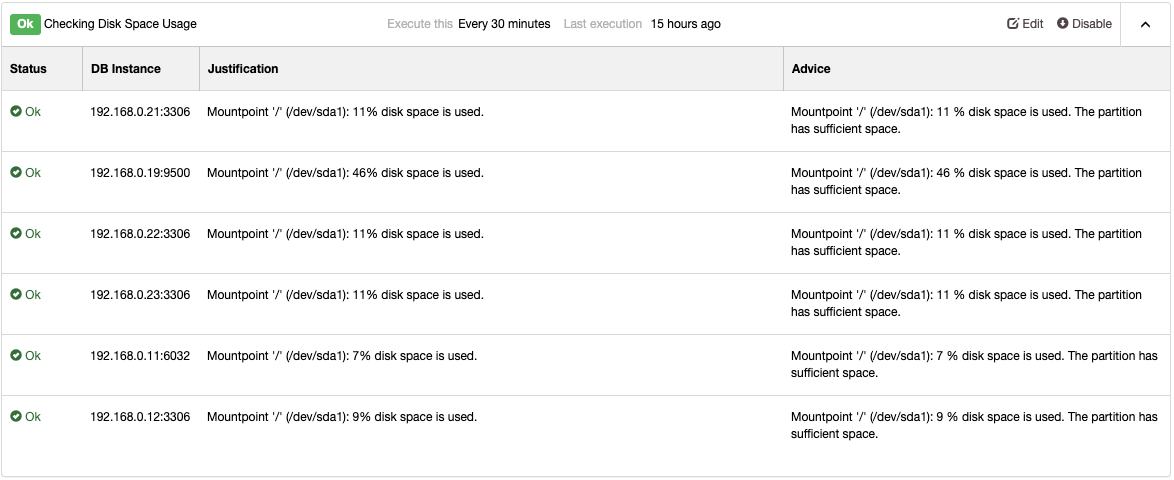
If you want monitoring specific to your database, then you will need to utilize external monitoring tools which have advanced, highly-granular database metrics. There are several choices you can choose from such as PMM by Percona, DataDog, Idera, VividCortex, or our very own ClusterControl (Monitoring is FREE with ClusterControl Community.)
Galera Cluster Database Security on Azure
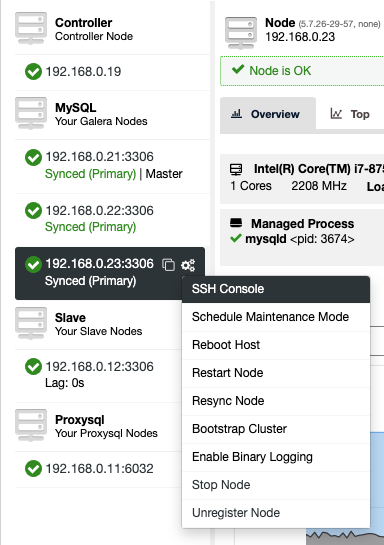
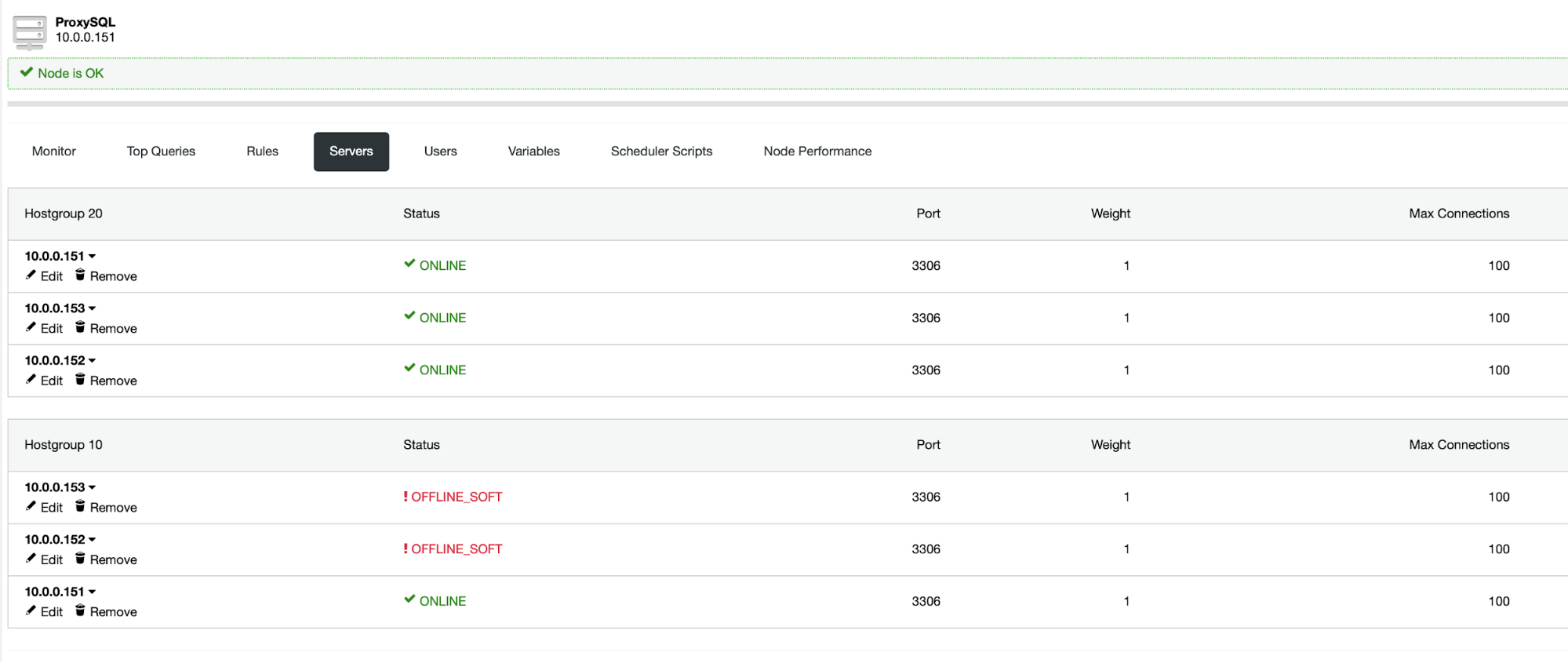
As discussed in our previous blogs for AWS and GCP, you can take the same approach for securing your database in the public cloud. Once you create a virtual machine, you can specify what ports only can be opened, or create and setup your Network Security Group in Azure. You can setup the ports need to be open (particularly ports 3306, 4444, 4567, 4568), or create a Virtual Network in Azure and specify the private subnets if they remain as a private node. To add this, if you setup your VM's in Azure without a public IP, it can still an outbound connection merely because it uses SNAT and PAT. If you're familiar with AWS and GCP, you'll like this explanation to make it easier to comprehend.
Another feature available is Role-Based Access Control in Microsoft Azure. This gives you control on which people that access to the specific resources they need.
In addition to this, you can secure your data-in-transit by using a TLS/SSL connection or by encrypting your data when it's at-rest. If you're using ClusterControl, deploying a secure data in-transit is simple and easy. You can check out our blog SSL Key Management and Encryption of MySQL Data in Transit if you want to try out. For data at-rest, you can follow the discussion I have stated earlier in the Encryption section of this blog.
Galera Cluster Troubleshooting
Microsoft Azure offers a wide array of log types to aid troubleshooting and auditing. The logs Activity logs, Azure diagnostics logs, Azure AD reporting, Virtual machines and cloud services, Network Security Group (NSG) flow logs, and Application insight are very useful when troubleshooting. It might not always be necessary to go into all of these when you need troubleshooting, however, it would add more insights and clues when checking the logs.
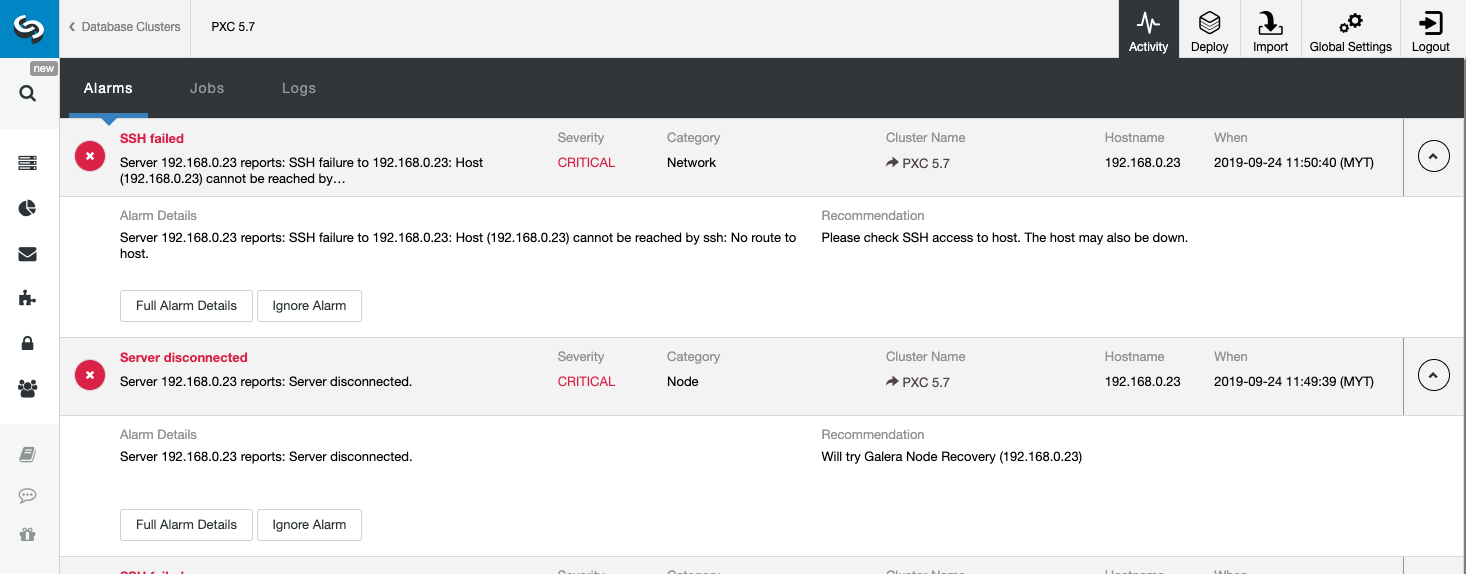
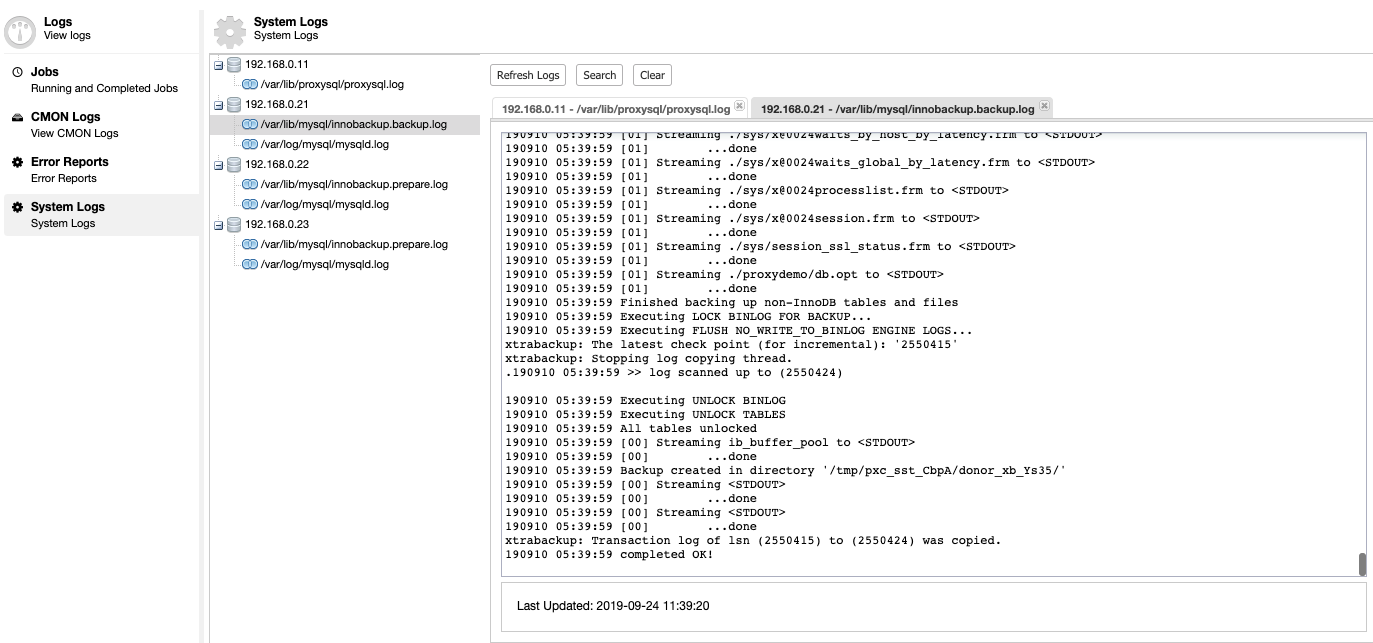
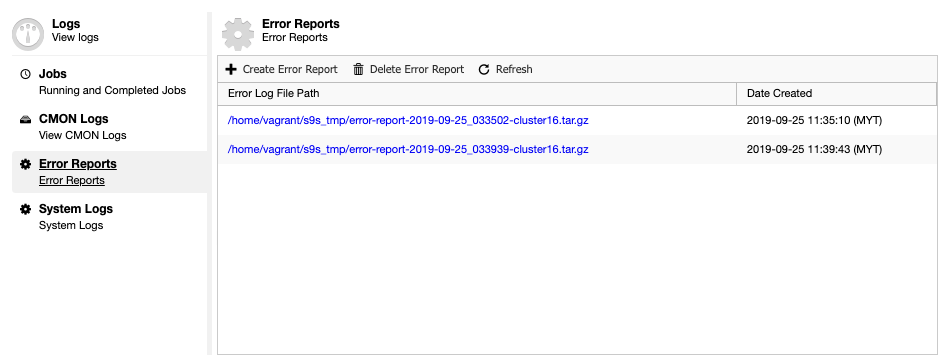
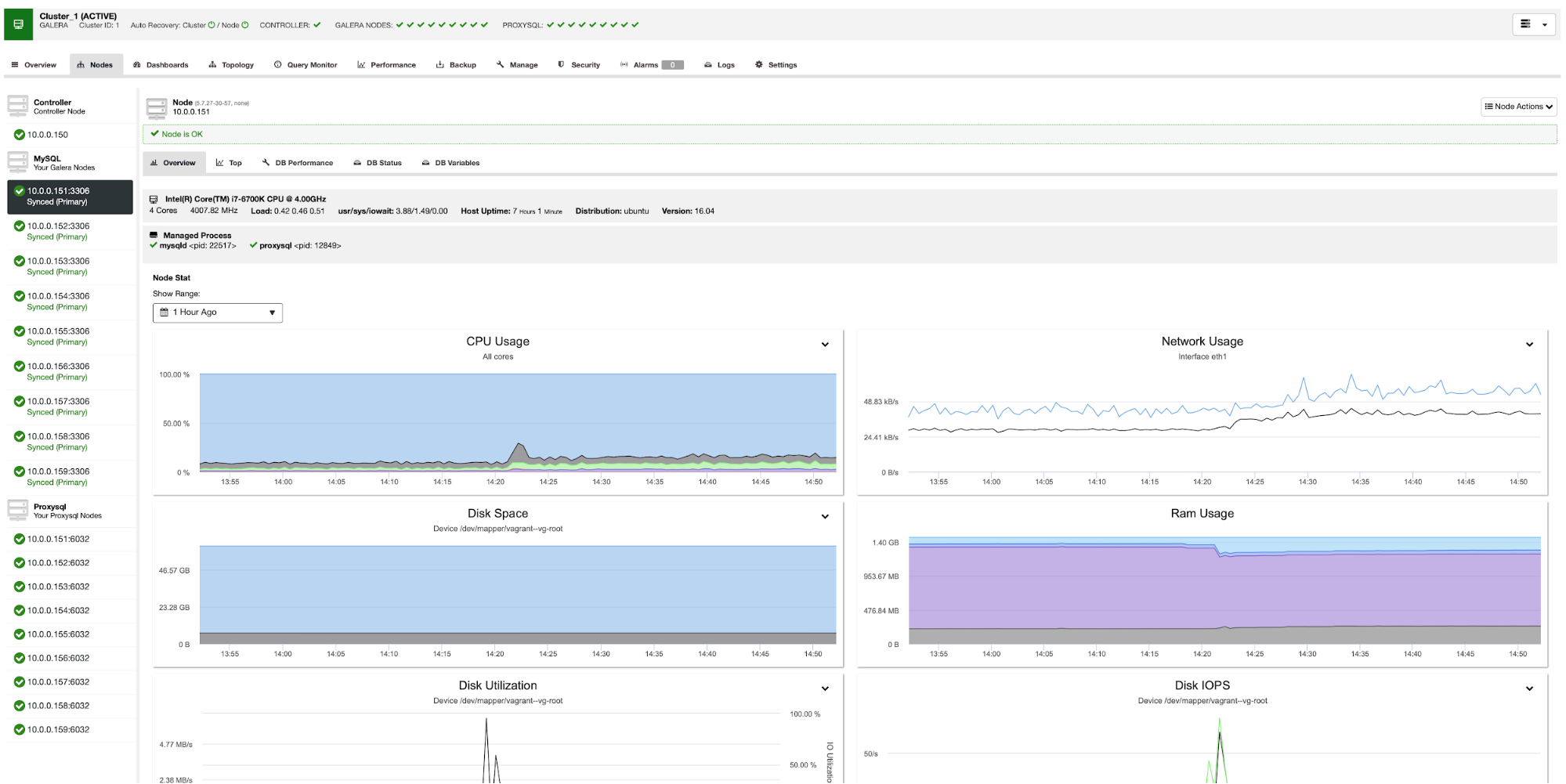
If you're using ClusterControl, going to Logs -> System Logs, and you'll be able to browse the captured error logs taken from the MySQL Galera node itself. Apart from this, ClusterControl provides real-time monitoring that would amplify your alarm and notification system in case an emergency or if your MySQL Galera node(s) is kaput.
Conclusion
As we finish this three part blog series, we have showed you the offerings and the advantages of each of the tech-giants serving the public cloud industry. There are advantages and disadvantages when selecting one over the other, but what matters most is your reason for moving to a public cloud, its benefits for your organization, and how it serves the requirements of your application.
The choice of provider for your Galera Cluster may involve financial considerations like “what's most cost-efficient” and better suits your budgetary needs. It could also be due to privacy laws and regulation compliance, or even because of the technology stack you are wanting to use. What's important is how your application and database will perform once it's in the cloud handling large amounts of traffic. It has to be highly-available, must be resilient, has the right levels of scalability and redundancy, and takes backups to ensure data recovery.