Business has continuously desired to derive insights from information to make reliable, smarter, real-time, fact-based decisions. As firms rely more on data and databases, information and data processing is the core of many business operations and business decisions. The faith in the database is total. None of the day-to-day company services can run without the underlying database platforms. As a consequence, the necessity on scalability and performance of database system software is more critical than ever. The principal benefits of the clustered database system are scalability and high availability. In this blog, we will try to compare Oracle RAC and Galera Cluster in the light of these two aspects. Real Application Clusters (RAC) is Oracle’s premium solution to clustering Oracle databases and provides High Availability and Scalability. Galera Cluster is the most popular clustering technology for MySQL and MariaDB.
Architecture overview
Oracle RAC uses Oracle Clusterware software to bind multiple servers. Oracle Clusterware is a cluster management solution that is integrated with Oracle Database, but it can also be used with other services, not only the database. The Oracle Clusterware is an additional software installed on servers running the same operating system, which lets the servers to be chained together to operate as if they were one server.
Oracle Clusterware watches the instance and automatically restarts it if a crash occurs. If your application is well designed, you may not experience any service interruption. Only a group of sessions (those connected to the failed instance) is affected by the failure. The blackout can be efficiently masked to the end user using advanced RAC features like Fast Application Notification and the Oracle client’s Fast Connection Failover. Oracle Clusterware controls node membership and prevents split brain symptoms in which two or more instances attempt to control the instance.
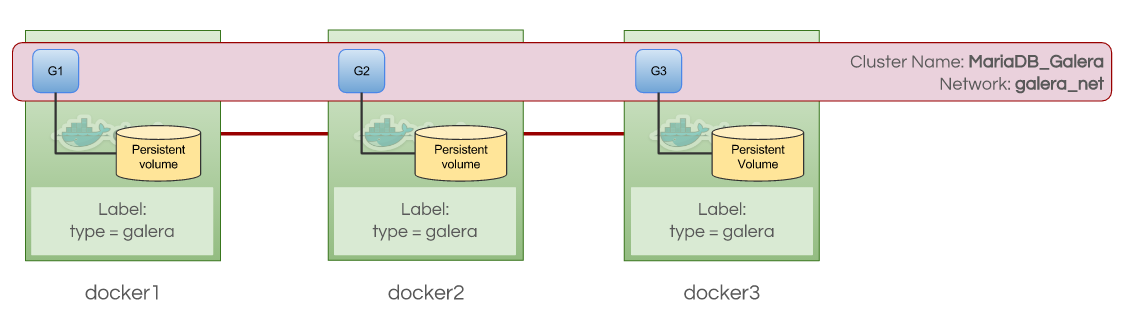
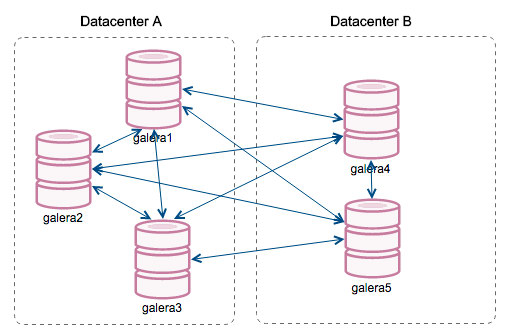
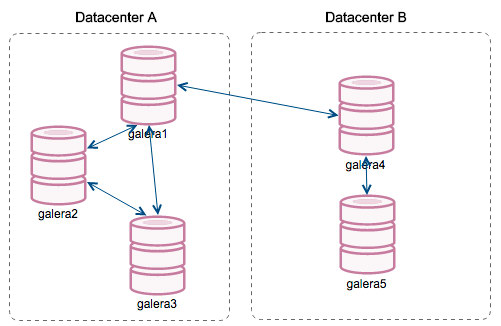
Galera Cluster is a synchronous active-active database clustering technology for MySQL and MariaDB. Galera Cluster differs from what is known as Oracle’s MySQL Cluster - NDB. MariaDB cluster is based on the multi-master replication plugin provided by Codership. Since version 5.5, the Galera plugin (wsrep API) is an integral part of MariaDB. Percona XtraDB Cluster (PXC) is also based on the Galera plugin. The Galera plugin architecture stands on three core layers: certification, replication, and group communication framework. Certification layer prepares the write-sets and does the certification checks on them, guaranteeing that they can be applied. Replication layer manages the replication protocol and provides the total ordering capability. Group Communication Framework implements a plugin architecture which allows other systems to connect via gcomm back-end schema.
To keep the state identical across the cluster, the wsrep API uses a Global Transaction ID. GTID unique identifier is created and associated with each transaction committed on the database node. In Oracle RAC, various database instances share access to resources such as data blocks in the buffer cache to enqueue data blocks. Access to the shared resources between RAC instances needs to be coordinated to avoid conflict. To organize shared access to these resources, the distributed cache maintains information such as data block ID, which RAC instance holds the current version of this data block, and the lock mode in which each instance contains the data block.
Data storage key concepts
Oracle RAC relies on a distributed disk architecture. The database files, control files and online redo logs for the database need be accessible to each node in the cluster. There is a variation of ways to configure shared storage including directly attached disks, Storage Area Networks (SAN), and Network Attached Storage (NAS) and Oracle ASM. Two most popular are OCFS and ASM. Oracle Cluster File System (OCFS) is a shared file system designed specifically for Oracle RAC. OCFS eliminates the requirement that Oracle database files be connected to logical drives and enables all nodes to share a single Oracle Home ASM, RAW Device. Oracle ASM is Oracle's advised storage management solution that provides an alternative to conventional volume managers, file systems, and raw devices. The Oracle ASM provides a virtualization layer between the database and storage. It treats multiple disks as a single disk group and lets you dynamically add or remove drives while maintaining databases online.
There is no need to build sophisticated shared disk storage for Galera, as each node has its full copy of data. However it is a good practice to make the storage reliable with battery-backed write caches.
![Oracle RAC, Cluster storage]()
Oracle RAC, Cluster storage
![Galera replication, disks attached to database nodes]()
Galera replication, disks attached to database nodes
Cluster nodes communication and cache
Oracle Real Application Clusters has a shared cache architecture, it utilizes Oracle Grid Infrastructure to enable the sharing of server and storage resources. Communication between nodes is the critical aspect of cluster integrity. Each node must have at least two network adapters or network interface cards: one for the public network interface, and one for the interconnect. Each cluster node is connected to all other nodes via a private high-speed network, also recognized as the cluster interconnect.
![Oracle RAC, network architecture]()
Oracle RAC, network architecture
The private network is typically formed with Gigabit Ethernet, but for high-volume environments, many vendors offer low-latency, high-bandwidth solutions designed for Oracle RAC. Linux also extends a means of bonding multiple physical NICs into a single virtual NIC to provide increased bandwidth and availability.
While the default approach to connecting Galera nodes is to use a single NIC per host, you can have more than one card. ClusterControl can assist you with such setup. The main difference is the bandwidth requirement on the interconnect. Oracle RAC ships blocks of data between instances, so it places a heavier load on the interconnect as compared to Galera write-sets (which consist of a list of operations).
With Redundant Interconnect Usage in RAC, you can identify multiple interfaces to use for the private cluster network, without the need of using bonding or other technologies. This functionality is available starting with Oracle Database 11gR2. If you use the Oracle Clusterware excessive interconnect feature, then you must use IPv4 addresses for the interfaces (UDP is a default).
To manage high availability, each cluster node is assigned a virtual IP address (VIP). In the event of node failure, the failed node's IP address can be reassigned to a surviving node to allow applications continue to reach the database through the same IP address.
Sophisticated network setup is necessary to Oracle's Cache Fusion technology to couple the physical memory in each host into a single cache. Oracle Cache Fusion provides data stored in the cache of one Oracle instance to be accessed by any other instance by transporting it across the private network. It also protects data integrity and cache coherency by transmitting locking and supplementary synchronization information beyond cluster nodes.
On top of the described network setup, you can set a single database address for your application - Single Client Access Name (SCAN). The primary purpose of SCAN is to provide ease of connection management. For instance, you can add new nodes to the cluster without changing your client connection string. This functionality is because Oracle will automatically distribute requests accordingly based on the SCAN IPs which point to the underlying VIPs. Scan listeners do the bridge between clients and the underlying local listeners which are VIP-dependent.
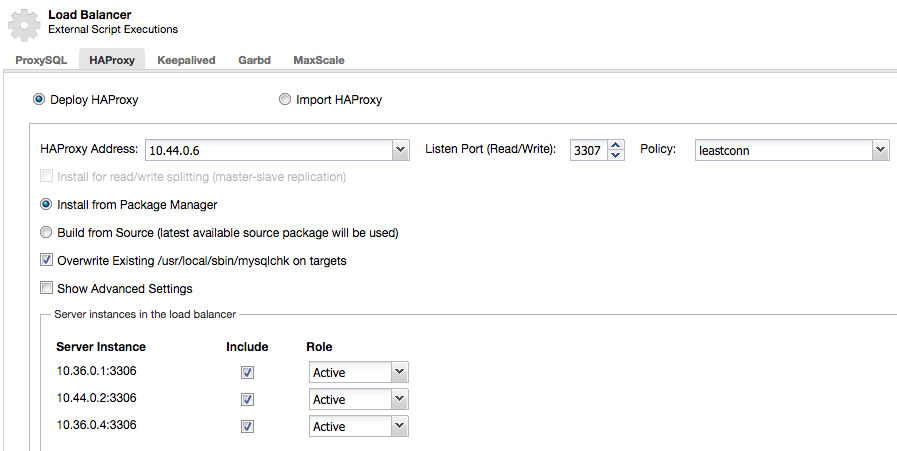
For Galera Cluster, the equivalent of SCAN would be adding a database proxy in front of the Galera nodes. The proxy would be a single point of contact for applications, it can blacklist failed nodes and route queries to healthy nodes. The proxy itself can be made redundant with Keepalived and Virtual IP.
Single Console for Your Entire Database Infrastructure
Find out what else is new in ClusterControl
Failover and data recovery
The main difference between Oracle RAC and MySQL Galera Cluster is that Galera is shared nothing architecture. Instead of shared disks, Galera uses certification based replication with group communication and transaction ordering to achieve synchronous replication. A database cluster should be able to survive a loss of a node, although it's achieved in different ways. In case of Galera, the critical aspect is the number of nodes, Galera requires a quorum to stay operational. A three node cluster can survive the crash of one node. With more nodes in your cluster, your availability will grow. Oracle RAC doesn't require a quorum to stay operational after a node crash. It is because of the access to distributed storage that keeps consistent information about cluster state. However, your data storage could be a potential point of failure in your high availability plan. While it's reasonably straightforward task to have Galera cluster nodes spread across geolocation data centers, it wouldn't be that easy with RAC. Oracle RAC requires additional high-end disk mirroring however, basic RAID like redundancy can be achieved inside an ASM diskgroup.
| Disk Group Type | Supported Mirroring Levels | Default Mirroring Level |
|---|
| External redundancy | Unprotected (none) | Unprotected |
| Normal redundancy | Two-way, three-way, unprotected (none) | Two-way |
| High redundancy | Three-way | Three-way |
| Flex redundancy | Two-way, three-way, unprotected (none) | Two-way (newly-created) |
| Extended redundancy | Two-way, three-way, unprotected (none) | Two-way |
ASM Disk Group redundancy
Locking Schemes
In a single-user database, a user can alter data without concern for other sessions modifying the same data at the same time. However, in a multi-user database multi-node environment, this become more tricky. A multi-user database must provide the following:
- data concurrency - the assurance that users can access data at the same time,
- data consistency - the assurance that each user sees a consistent view of the data.
Cluster instances require three main types of concurrency locking:
- Data concurrency reads on different instances,
- Data concurrency reads and writes on different instances,
- Data concurrency writes on different instances.
Oracle lets you choose the policy for locking, either pessimistic or optimistic, depending on your requirements. To obtain concurrency locking, RAC has two additional buffers. They are Global Cache Service (GCS) and Global Enqueue Service (GES). These two services cover the Cache Fusion process, resource transfers, and resource escalations among the instances. GES include cache locks, dictionary locks, transaction locks and table locks. GCS maintains the block modes and block transfers between the instances.
In Galera cluster, each node has its storage and buffers. When a transaction is started, database resources local to that node are involved. At commit, the operations that are part of that transaction are broadcasted as part of a write-set, to the rest of the group. Since all nodes have the same state, the write-set will either be successful on all nodes or it will fail on all nodes.
Galera Cluster uses at the cluster-level optimistic concurrency control, which can appear in transactions that result in a COMMIT aborting. The first commit wins. When aborts occur at the cluster level, Galera Cluster gives a deadlock error. This may or may not impact your application architecture. High number of rows to replicate in a single transaction would impact node responses, although there are techniques to avoid such behavior.
Hardware & Software requirements
Configuring both clusters hardware doesn’t require potent resources. Minimal Oracle RAC cluster configuration would be satisfied by two servers with two CPUs, physical memory at least 1.5 GB of RAM, an amount of swap space equal to the amount of RAM and two Gigabit Ethernet NICs. Galera’s minimum node configuration is three nodes (one of nodes can be an arbitrator, gardb), each with 1GHz single-core CPU 512MB RAM, 100 Mbps network card. While these are the minimal, we can safely say that in both cases you would probably like to have more resources for your production system.
Each node stores software so you would need to prepare several gigabytes of your storage. Oracle and Galera both have the ability to individually patch the nodes by taking them down one at a time. This rolling patch avoids a complete application outage as there are always database nodes available to handle traffic.
What is important to mention is that a production Galera cluster can easily run on VM’s or basic bare metal, while RAC would need investment in sophisticated shared storage and fiber communication.
Monitoring and management
Oracle Enterprise Manager is the favored approach for monitoring Oracle RAC and Oracle Clusterware. Oracle Enterprise Manager is an Oracle Web-based unified management system for monitoring and administering your database environment. It’s part of Oracle Enterprise License and should be installed on separate server. Cluster control monitoring and management is done via combination on crsctl and srvctl commands which are part of cluster binaries. Below you can find a couple of example commands.
Clusterware Resource Status Check:
crsctl status resource -t (or shorter: crsctl stat res -t)
Example:
$ crsctl stat res ora.test1.vip
NAME=ora.test1.vip
TYPE=ora.cluster_vip_net1.type
TARGET=ONLINE
STATE=ONLINE on test1
Check the status of the Oracle Clusterware stack:
crsctl check cluster
Example:
$ crsctl check cluster -all
*****************************************************************
node1:
CRS-4537: Cluster Ready Services is online
CRS-4529: Cluster Synchronization Services is online
CRS-4533: Event Manager is online
*****************************************************************
node2:
CRS-4537: Cluster Ready Services is online
CRS-4529: Cluster Synchronization Services is online
CRS-4533: Event Manager is online
Check the status of Oracle High Availability Services and the Oracle Clusterware stack on the local server:
crsctl check crs
Example:
$ crsctl check crs
CRS-4638: Oracle High Availablity Services is online
CRS-4537: Cluster Ready Services is online
CRS-4529: Cluster Synchronization Services is online
CRS-4533: Event Manager is online
Stop Oracle High Availability Services on the local server.
crsctl stop has
Stop Oracle High Availability Services on the local server.
crsctl start has
Displays the status of node applications:
srvctl status nodeapps
Displays the configuration information for all SCAN VIPs
srvctl config scan
Example:
srvctl config scan -scannumber 1
SCAN name: testscan, Network: 1
Subnet IPv4: 192.51.100.1/203.0.113.46/eth0, static
Subnet IPv6:
SCAN 1 IPv4 VIP: 192.51.100.195
SCAN VIP is enabled.
SCAN VIP is individually enabled on nodes:
SCAN VIP is individually disabled on nodes:
The Cluster Verification Utility (CVU) performs system checks in preparation for installation, patch updates, or other system changes:
cluvfy comp ocr
Example:
Verifying OCR integrity
Checking OCR integrity...
Checking the absence of a non-clustered configurationl...
All nodes free of non-clustered, local-only configurations
ASM Running check passed. ASM is running on all specified nodes
Checking OCR config file “/etc/oracle/ocr.loc"...
OCR config file “/etc/oracle/ocr.loc" check successful
Disk group for ocr location “+DATA" available on all the nodes
NOTE:
This check does not verify the integrity of the OCR contents. Execute ‘ocrcheck' as a privileged user to verify the contents of OCR.
OCR integrity check passed
Verification of OCR integrity was successful.
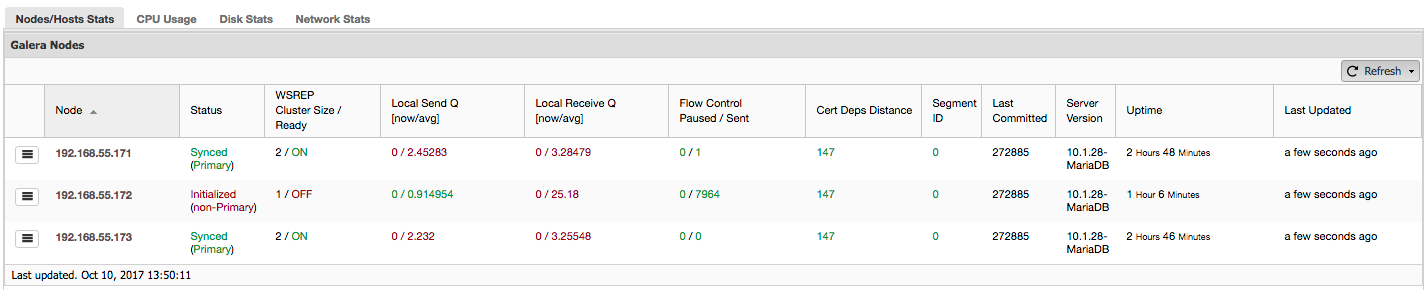
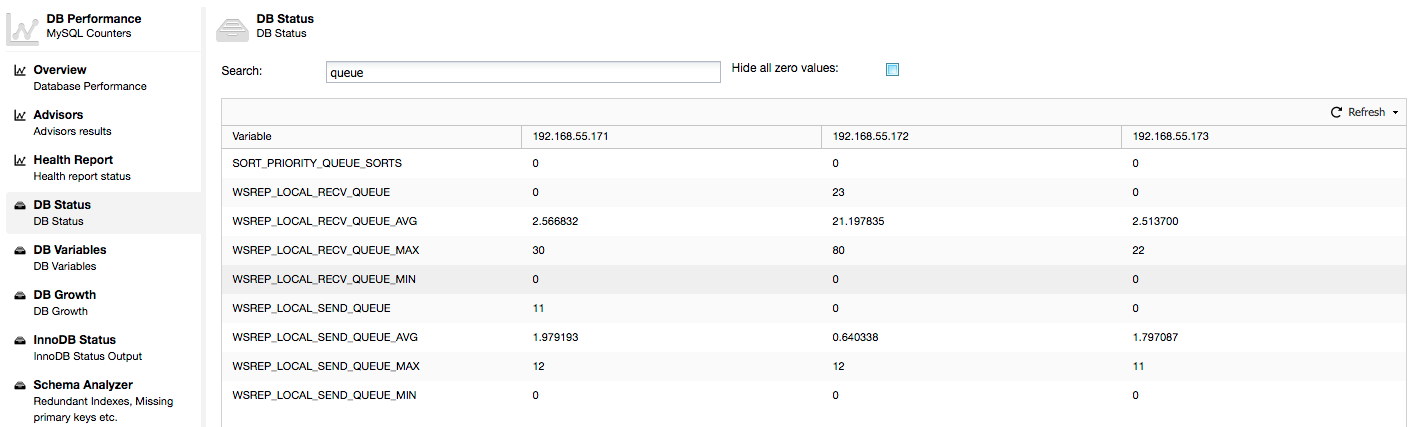
Galera nodes and the cluster requires the wsrep API to report several statuses, which is exposed. There are currently 34 dedicated status variables can be viewed with SHOW STATUS statement.
mysql> SHOW STATUS LIKE 'wsrep_%';
wsrep_apply_oooe
wsrep_apply_oool
wsrep_cert_deps_distance
wsrep_cluster_conf_id
wsrep_cluster_size
wsrep_cluster_state_uuid
wsrep_cluster_status
wsrep_connected
wsrep_flow_control_paused
wsrep_flow_control_paused_ns
wsrep_flow_control_recv | wsrep_local_send_queue_avg
wsrep_local_state_uuid
wsrep_protocol_version
wsrep_provider_name
wsrep_provider_vendor
wsrep_provider_version
wsrep_flow_control_sent
wsrep_gcomm_uuid
wsrep_last_committed
wsrep_local_bf_aborts
wsrep_local_cert_failures | wsrep_local_commits
wsrep_local_index
wsrep_local_recv_queue
wsrep_local_recv_queue_avg
wsrep_local_replays
wsrep_local_send_queue
wsrep_ready
wsrep_received
wsrep_received_bytes
wsrep_replicated
wsrep_replicated_bytes
wsrep_thread_count |
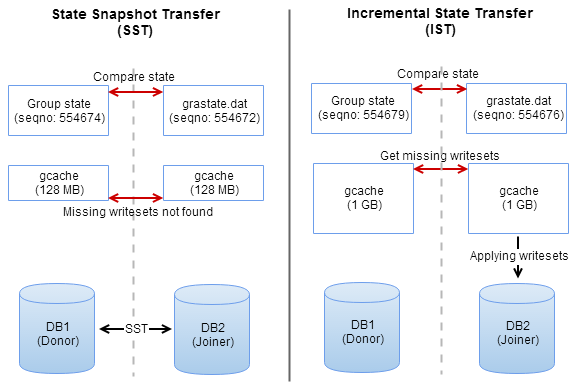
The administration of MySQL Galera Cluster in many aspects is very similar. There are just few exceptions like bootstrapping the cluster from initial node or recovering nodes via SST or IST operations.
Bootstrapping cluster:
$ service mysql bootstrap # sysvinit
$ service mysql start --wsrep-new-cluster # sysvinit
$ galera_new_cluster # systemd
$ mysqld_safe --wsrep-new-cluster # command line
The equivalent Web-based, out of the box solution to manage and monitor Galera Cluster is ClusterControl. It provides a web-based interface to deploy clusters, monitors key metrics, provides database advisors, and take care of management tasks like backup and restore, automatic patching, traffic encryption and availability management.
Restrictions on workload
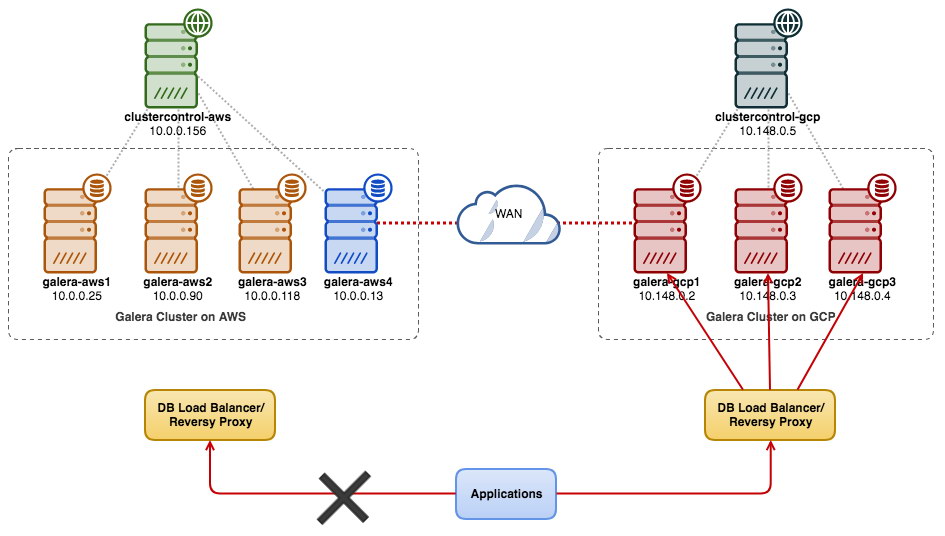
Oracle provides SCAN technology which we found missing in Galera Cluster. The benefit of SCAN is that the client’s connection information does not need to change if you add or remove nodes or databases in the cluster. When using SCAN, the Oracle database randomly connects to one of the available SCAN listeners (typically three) in a round robin fashion and balances the connections between them. Two kinds load balancing can be configured: client side, connect time load balancing and on the server side, run time load balancing. Although there is nothing similar within Galera cluster itself, the same functionality can be addressed with additional software like ProxySQL, HAProxy, Maxscale combined with Keepalived.
When it comes to application workload design for Galera Cluster, you should avoid conflicting updates on the same row, as it leads to deadlocks across the cluster. Avoid bulk inserts or updates, as these might be larger than the maximum allowed writeset. That might also cause cluster stalls.
Designing Oracle HA with RAC you need to keep in mind that RAC only protects against server failure, and you need to mirror the storage and have network redundancy. Modern web applications require access to location-independent data services, and because of RAC’s storage architecture limitations, it can be tricky to achieve. You also need to spend a notable amount of time to gain relevant knowledge to manage the environment; it is a long process. On the application workload side, there are some drawbacks. Distributing separated read or write operations on the same dataset is not optimal because latency is added by supplementary internode data exchange. Things like partitioning, sequence cache, and sorting operations should be reviewed before migrating to RAC.
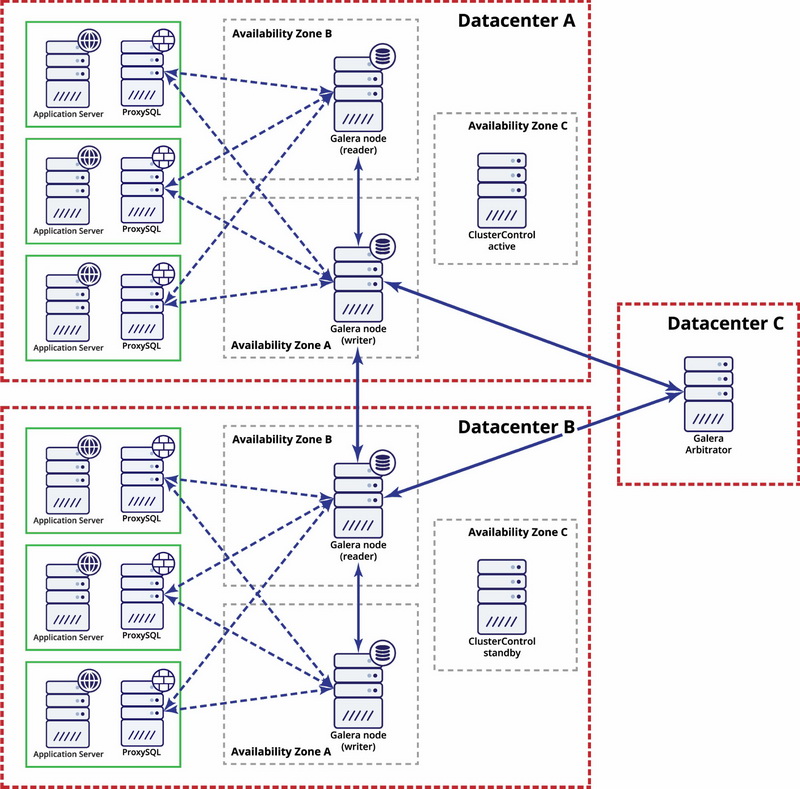
Multi data-center redundancy
According to the Oracle documentation, the maximum distance between two boxes connected in a point-to-point fashion and running synchronously can be only 10 km. Using specialized devices, this distance can be increased to 100 km.
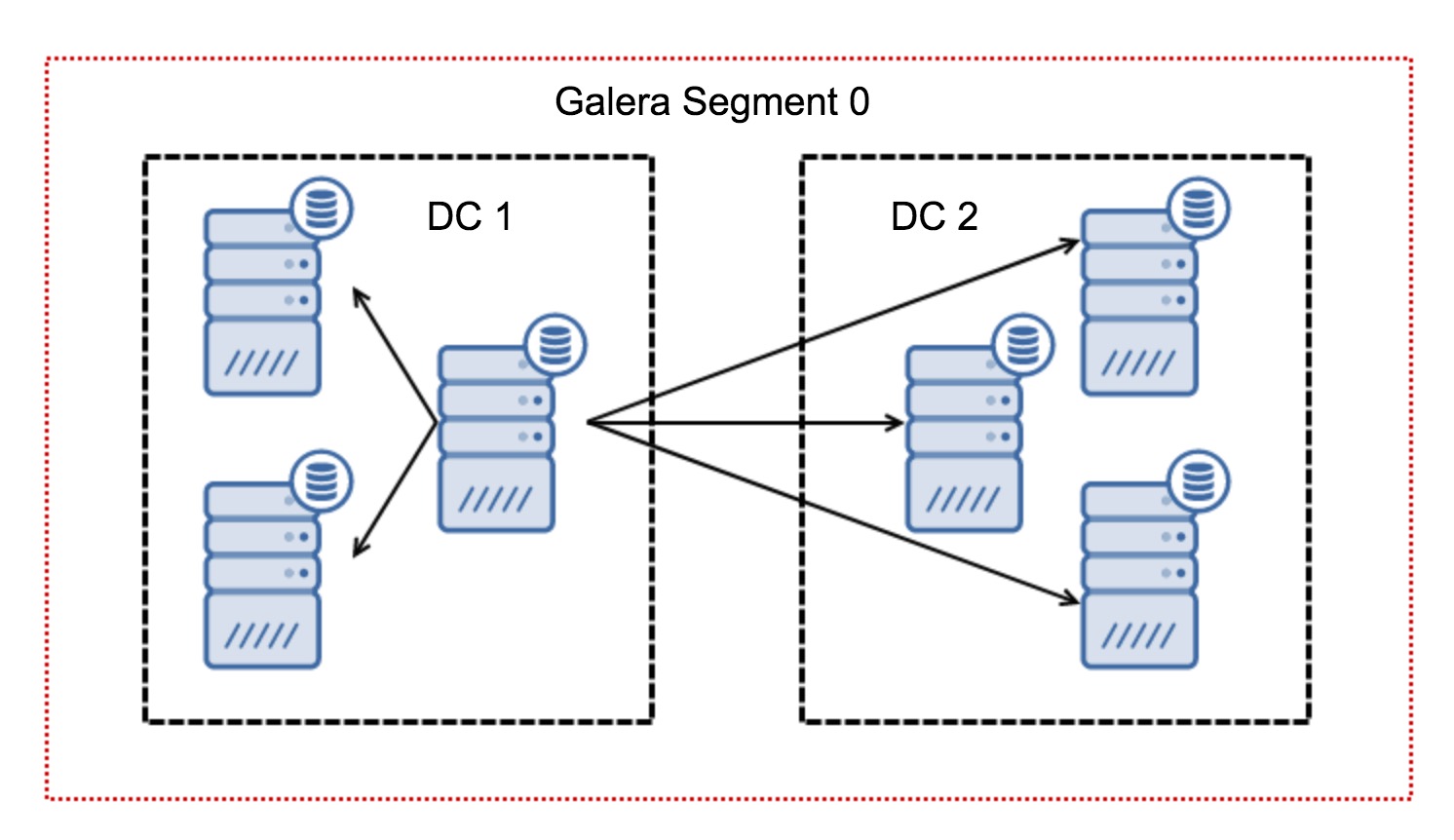
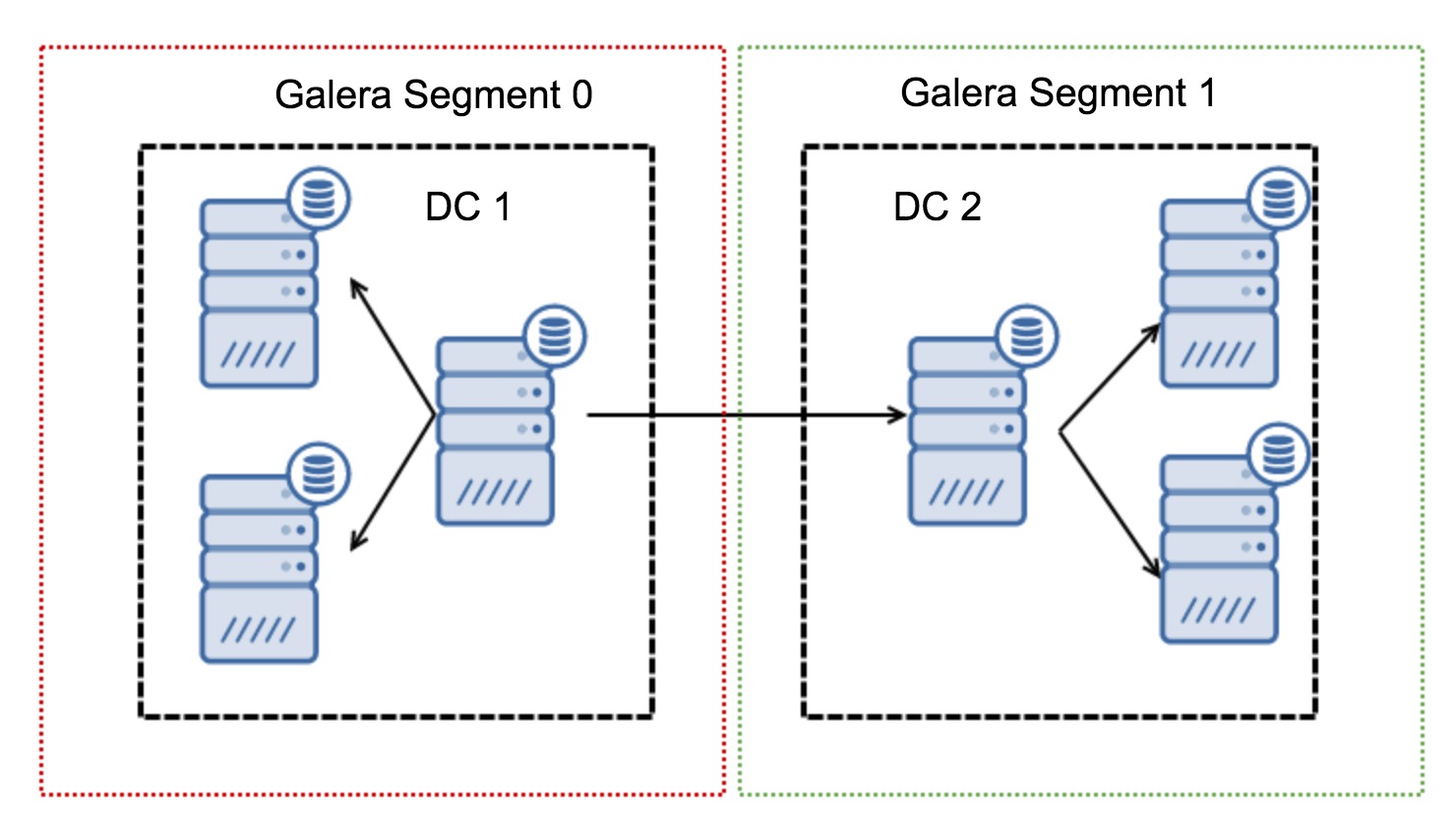
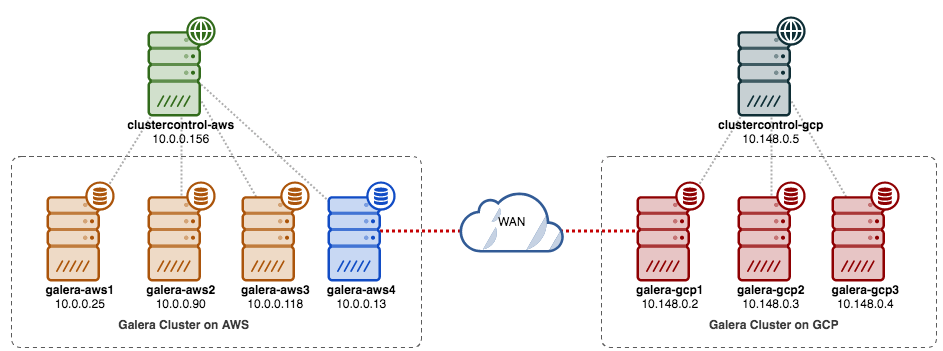
Galera Cluster is well known for its multi-datacenter replication capabilities. It has rich support for Wider Area Networks network settings. It can be configured for high network latency by taking Round-Trip Time (RTT) measurements between cluster nodes and adjusting necessary parameters. The wsrep_provider_options parameters allow you to configure settings like suspect_timeout, interactive_timeout, join_retrans_timouts and many more.
Using Galera and RAC in Cloud
Per Oracle note www.oracle.com/technetwork/database/options/.../rac-cloud-support-2843861.pdf no third-party cloud currently meets Oracle’s requirements regarding natively provided shared storage. “Native” in this context means that the cloud provider must support shared storage as part of their infrastructure as per Oracle’s support policy.
Thanks to its shared nothing architecture, which is not tied to a sophisticated storage solution, Galera cluster can be easily deployed in a cloud environment. Things like:
- optimized network protocol,
- topology-aware replication,
- traffic encryption,
- detection and automatic eviction of unreliable nodes,
makes cloud migration process more reliable.
Licenses and hidden costs
Oracle licensing is a complex topic and would require a separate blog article. The cluster factor makes it even more difficult. The cost goes up as we have to add some options to license a complete RAC solution. Here we just want to highlight what to expect and where to find more information.
RAC is a feature of Oracle Enterprise Edition license. Oracle Enterprise license is split into two types, per named user and per processor. If you consider Enterprise Edition with per core license, then the single core cost is RAC 23,000 USD + Oracle DB EE 47,500 USD, and you still need to add a ~ 22% support fee. We would like to refer to a great blog on pricing found on https://flashdba.com/2013/09/18/the-real-cost-of-oracle-rac/.
Flashdba calculated the price of a four node Oracle RAC. The total amount was 902,400 USD plus additional 595,584 USD for three years DB maintenance, and that does not include features like partitioning or in-memory database, all that with 60% Oracle discount.
Galera Cluster is an open source solution that anyone can run for free. Subscriptions are available for production implementations that require vendor support. A good TCO calculation can be found at https://severalnines.com/blog/database-tco-calculating-total-cost-ownership-mysql-management.
Conclusion
While there are significant differences in architecture, both clusters share the main principles and can achieve similar goals. Oracle enterprise product comes with everything out of the box (and it's price). With a cost in the range of >1M USD as seen above, it is a high-end solution that many enterprises would not be able to afford. Galera Cluster can be described as a decent high availability solution for the masses. In certain cases, Galera may well be a very good alternative to Oracle RAC. One drawback is that you have to build your own stack, although that can be completely automated with ClusterControl. We’d love to hear your thoughts on this.