Database encryption provides enhanced security for your at rest and in transit data. Many organisations have started to look at data encryption seriously with recent security breach cases. In most cases, database servers are a common target for attackers because it holds the most valuable asset for most organisations. Once an intruder has gained access to valuable data from your server, chances are they will steal the data from it. They then use the data for ransom, data exploitation or other financial gains from the organisation they have attacked.
In this blog, we discuss why database encryption is important and how data encryption plays a significant role in securing your database.
Why Do I Need Database Encryption?
Database encryption is a process to convert data in the database to “cipher text” (unreadable text) using an algorithm. You need to use a key generated from the algorithm to decrypt the text. The database encryption process is highly recommendable, especially for businesses dealing with financial, health care, or e-commerce. Recently cyber attacks, data theft, or data breaches have been rampant; therefore, there is an increasing concern over private data. People are very aware of data privacy, security and want their data to be protected and used only when required. Following are some good benefits of having database encryption:
Avoid Security Attacks
Security attacks are inevitable, but with better security and data encryption methods, intruders might not analyse or decrypt to understand the data further in a data breach. Suppose a Man-in-the-middle (MITM) attack or eavesdropping is happening during backup or transfers between servers. If this is an unencrypted data transfer, it is definitely advantageous to the attackers; not a situation you want to have in your environment!
If you have an encrypted database, an attacker must find ways to decrypt the encrypted data. How far they could go depends on the cyphers' complexity and algorithms applied to generate the encrypted data. Also, attackers will try their best to access encryption keys, leading them to open the vault or decrypt the encrypted data, similar to gold mining; after all, data is the new gold these days. To avoid these kinds of data breach attempts, it is important to secure the infrastructure in all ways, including limiting access to servers where possible.
Compliance with Security Regulations
When dealing with security regulations such as PCI-DSS, encryption is one of the most important requirements. It is a mandatory requirement. For instance, all cardholder data must be either encrypted using industry-accepted algorithms (e.g. AES-256, RSA 2048), truncated, tokenized, or hashed (approved hash algorithms specified in FIPS 180-4: SHA-1, SHA-224, SHA-256, SHA-384 SHA-512, SHA-512/224 and SHA-512/256). Although that is not the only thing to be covered for having encrypted data, PCI-DSS also requires the coverage of using PCI-DSS encryption key management process.
Protecting Sensitive Data
The encryption key management is ideal for protecting sensitive data with centralized key management and simple APIs for data encryption. Examples of these key management are using Hashicorp Vault (open source) or if you are using public cloud (closed source), most commonly closed-source key management are Amazon Web Service (AWS) Key Management Service (KMS), Google Cloud KMS, Microsoft Azure Key Vault.
What is Data Encryption?
Encryption is one of the most important security features to keep your data as secure as possible. Depending on the data you are handling, it is not always a must, but you should at least consider it a security improvement in your organization. In fact, it is actually recommended to avoid data theft or unauthorized access.
Data encryption is a process of encoding the data. It is mainly a two-way function, which means encrypted data has to be decrypted with a valid encryption key. Encryption is one such technique of Cryptography. Encryption is a way to conceal information by altering it so that it appears to be random data - encryption methods can make your data (for example messages) confidential, but at the same time, other techniques and strategies are required to provide the integrity and authenticity of a message. Encryption is more of a mathematical operation.
In database encryption, there are two basic types when it comes to encrypting the data. These encryption types are data at-rest and data in-transit. Let’s see what they mean.
Data at-Rest Encryption
Data stored in a system is known as data at-rest. The encryption of this data consists of using an algorithm to convert text or code for it to be unreadable. You must have an encryption key to decode the encrypted data.
Encrypting an entire database should be done with caution since it can result in a serious performance impact. It is therefore wise to encrypt only individual fields or tables. Encrypting data-at-rest protects the data from physical theft of hard drives or unauthorized file storage access. This encryption also complies with data security regulations, especially if there is financial or health data stored on the filesystem.
Encryption for data at-rest: Where it applies?
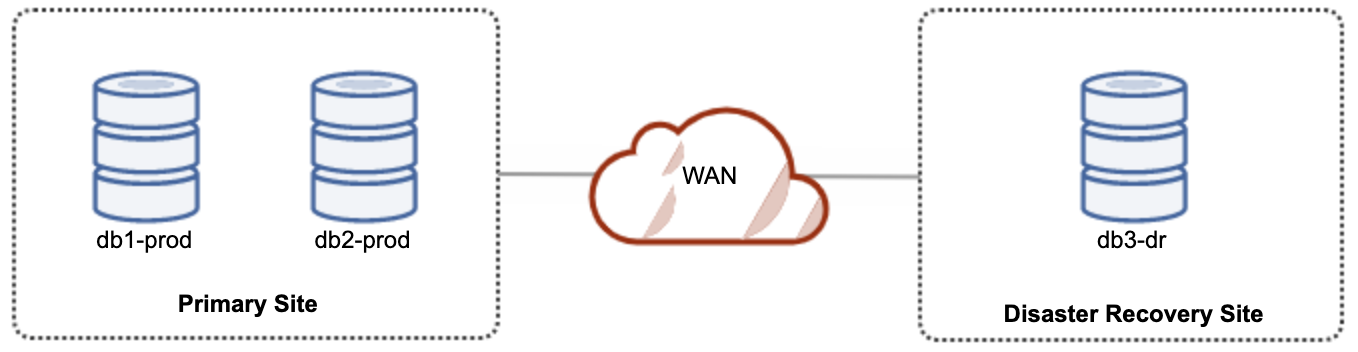
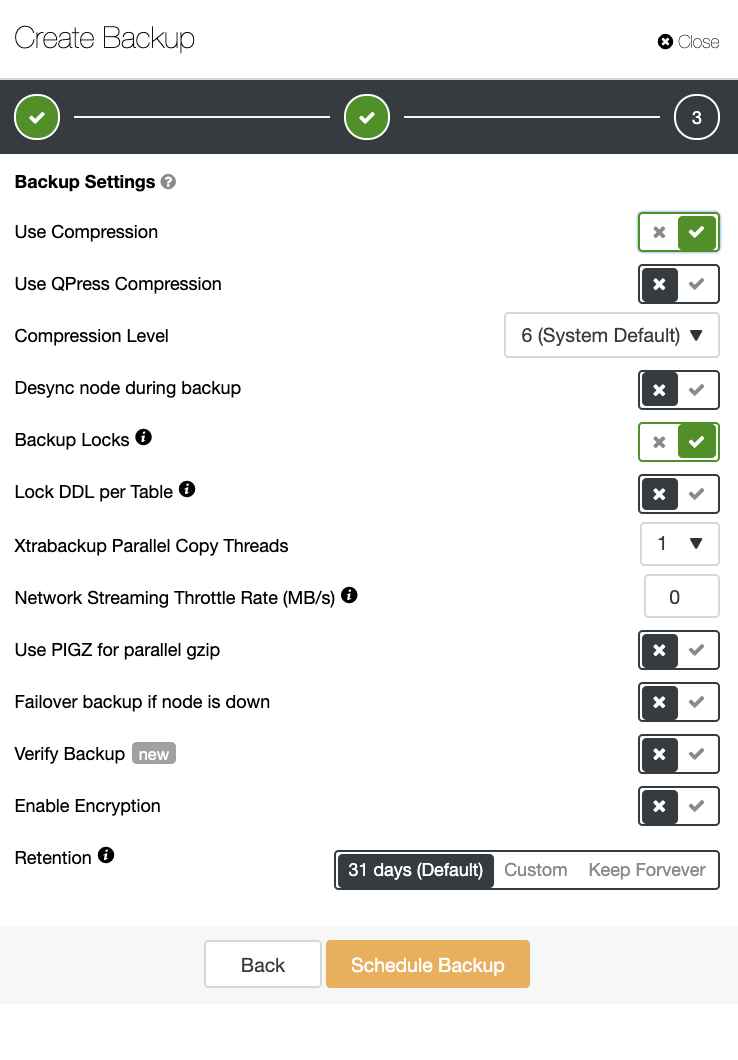
This covers data at-rest such as your database data stored in a specific location. For example, your PostgreSQL's data_directory, MySQL/MariaDB data_dir, or MongoDB's dbPath storage locations. Common process for providing encryption is using Transparent Data Encryption (TDE). The concept mainly is encrypting everything that is persistent.
Besides that, database backups are very prone to data theft and unauthorized access. These are stored physically in a non-volatile storage.While these setups are held exposed to be read by unauthorized access or data theft, encrypting the data helps avoid unwanted access. Of course, it also comes with securing your encryption keys somewhere hidden and not stored on the same server. Encrypting your database data stored as binaries and your backups whether it's a logical or a binary backup, keep in mind that encrypted data affects performance and makes the file size bigger.
Data in-Transit Encryption
Data transferred or moving around between transactions is known as data-in-transit. The data moving between the server and client while browsing web pages is a good example of this kind of data. Since it is always on the move, it needs to be encrypted to avoid any theft or alteration to the data before it reaches its destination.
The ideal situation to protect data-in-transit is to have the data encrypted before it moves, and decrypted once it reaches the final destination.
Encryption for data in-transit: Where it applies?
As specified above, this relates to the communication channel between the database client and the database server. Consider the application server and database server channels that have been compromised, and the attacker or intruder is eavesdropping or making a MITM attack. The attacker can listen and capture the data that is being sent over an insecure channel. This can be avoided if the data sent over the wire from its database client and database server communication channel is encrypted using TLS/SSL encryption.
Dealing with database encryption has a lot of challenges to overcome as well. Although there are advantages, there are cases that it is a disadvantage. Let's go over what these are.
Advantages of Data Encryption
Here are the lists of common and real-world cases that seek data encryption as an advantage.
It provides security for all of your data at all times
Protects privacy and sensitive information at all times
Protects your data across devices
Secure your government regulatory compliance
It gives you edge for being a competitive advantage
Presence of underlying technology for encryption for data protection could increase trust
Encrypted data maintains integrity
Disadvantages of Data Encryption
Data encryption doesn't mean business success. It doesn't give you the edge as a growing, innovative and advanced technology without knowing its challenges and best practices to implement and deal with this. It's true for the saying that "All That Glitters Is Not Gold". There are certain disadvantages if you have data encryption when you do not understand its main purpose.
Data encryption and performance penalties
Encryption involves complex and sophisticated mathematical operations to conceal the meaning of data. Depending on what types of ciphers or algorithms you choose either for hashing or deciphering the data. The complex and the higher bits are, if your database is designed to handle tons of requests, then it shall bog down your resources especially the CPU. Setting up data encryption such as TLS for your in-transit or using RSA 2048 bits can be too much if your financial capacity has not overseen this type of consequence. It is a resource intensive and adds extra pressure on the system's processor. Although modern computing systems are powerful and are affordable especially for public cloud offerings can be acceptable. Prepare some assessment first and identify what sort of performance impact encryption will have in the context where you will use it. It’s also important to understand that the performance of the various encryption solutions is different. Which means the need for speed and security have to be carefully balanced against one another.
Losing the data encryption keys
It's becoming common to store the encryption keys in a secure vault, as mentioned earlier, such as Hashicorp Vault, AWS KMS, and others. One major issue of having encryption is that if someone loses the decryption key, that would mean big trouble. You can relate that it is much the same as having a password, but it is treated as a global key to decrypt all the encrypted data. Not unless you have different encryption keys for every aspect of your database, then that could mean a lot of passwords to be remembered and has to be kept securely.
Data encryption impacts recovery time
If your data at-rest such as backups are encrypted, in case of a total disaster, recovering with your own backup can double or triple the time or even much more depending on how you have set the type of algorithm or ciphers. This adds pressure whenever you need your cluster and application to be up on time but cannot due to deciphering or decrypting the data takes too much time and system resources.
Limited protection against application level or insider attacks
Of course, this is understandable by the essence of having encryption. But this doesn't mean you don't have to encrypt anymore just because it doesn't apply protection in the application level. Of course, that's another layer of security that has to be applied in the application layer. Definitely, if someone gains access to your database user/password especially with administrative access, then encryption doesn't help here. The attacker can retrieve data by running a series of SQL queries which is of course human readable unless there is a certain level of application logic that encrypts the true meaning of your data. On the other hand, that just adds extra work and complexity of the overall tied up technology that you are using. If you have a large team that is designated to each of these layers, then that's a great advantage as managing the complexity can only be dedicated to every role they are supposed to focus on.
Cooperation and trust with peers holding the data encryption keys
Definitely a good thing to consider here. What if the peer who knows the keys and where it has been stored or your storage vault's password has left? It's very important to designate the physical access of the server where the keys and passwords are stored. Designation of the role and limiting access to these keys and passwords is very important. It also helps if you have a long and complex combination of passwords so that it shall be hard to memorize but at the same time shall be easily retrieved when needed. Although that sounds ironic, a secret has to remain sacred.
Should I Care About Data Encryption?
Data encryption is desirable and often mandatory, as mentioned, depending on your application's schematic process and design and level of business you are engaged with.
Should you care about data encryption? Definitely yes. It comes up as well, with personal dependency and business purpose. However, in the presence of sensitive data, especially when you have already built your own persona and financial capacity in your organization and company, all data are very much at a higher level of sensitivity. You do not want someone to steal your data and know all the strategic and business things involved in your company's growth. Data, in this case, has to be secured; thus, encryption is an essential aspect of securing your database and the data itself.
Conclusion
As sensitive data always exists even in our personal daily lives, the volume of sensitive and valuable data increases in parallel in an organisation. It is important to understand not all data requires encryption. Definitely, some data is globally shared or frequently repurposed; this type of data does not need to be encrypted. Take note of the advantages and disadvantages of using encryption in your database. Determining where it shall apply and how to apply it helps you achieve a secure environment without any performance impact.