MySQL 5.6 has an extensive list of new features and changes, so upgrading from a previous version can be risky if not tested extensively. For this reason, we recommend our users to read and understand the changes before doing the upgrade. If you are on older MySQL versions, it is probably time to think about upgrading. MySQL 5.6 was released in February 2013, that’s almost two years ago!
![]()
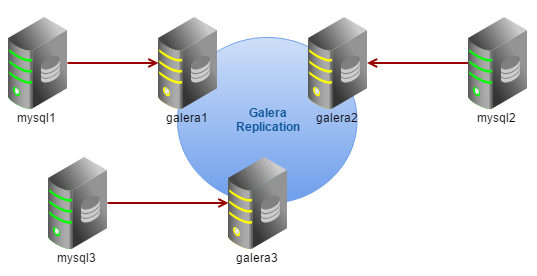
A major upgrade, e.g., from MySQL 5.5 to 5.6 or MariaDB 5.5 to 10, requires the former MySQL/MariaDB server related packages to be uninstalled. In Galera Cluster, there are two ways to upgrade; either by performing offline upgrade (safer, simpler, requires service downtime) or online upgrade (more complex, no downtime).
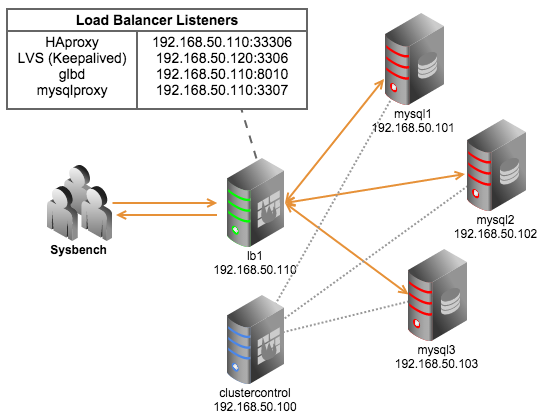
In this blog post, we are going to show you how to perform an offline upgrade on Galera-based MySQL/MariaDB servers, from MySQL 5.5.x to 5.6 or MariaDB 5.5 to 10.x with Galera 3.x, on Redhat and Debian-based systems. The online upgrade procedure will be covered in a separate post. Prior to the upgrade, determine the database vendor and operating system that is running at ClusterControl > Settings > General Settings > Version:
![]()
Note that different database vendor and operating system combinations use different installation steps, package names, versions and dependencies.
Offline Upgrade in Galera
Offline upgrade is recommended if you can afford scheduled downtime. The steps are straightforward and the probability for failure is significantly lower. Performing an online upgrade gives you availability at the cost of operational simplicity.
When performing an offline upgrade, the following steps are required:
- Stop the Galera cluster
- Remove the existing MySQL/MariaDB 5.5 related packages
- Install the MySQL 5.6/MariaDB 10.x related packages
- Perform post-installation configuration
- Execute mysql_upgrade command
- Start the Galera cluster
Pre-Upgrade
Before performing a major upgrade, you need to have following list checked:
- Read and understand the changes that are going to happen with the new version
- Note the unsupported configuration options between the major versions
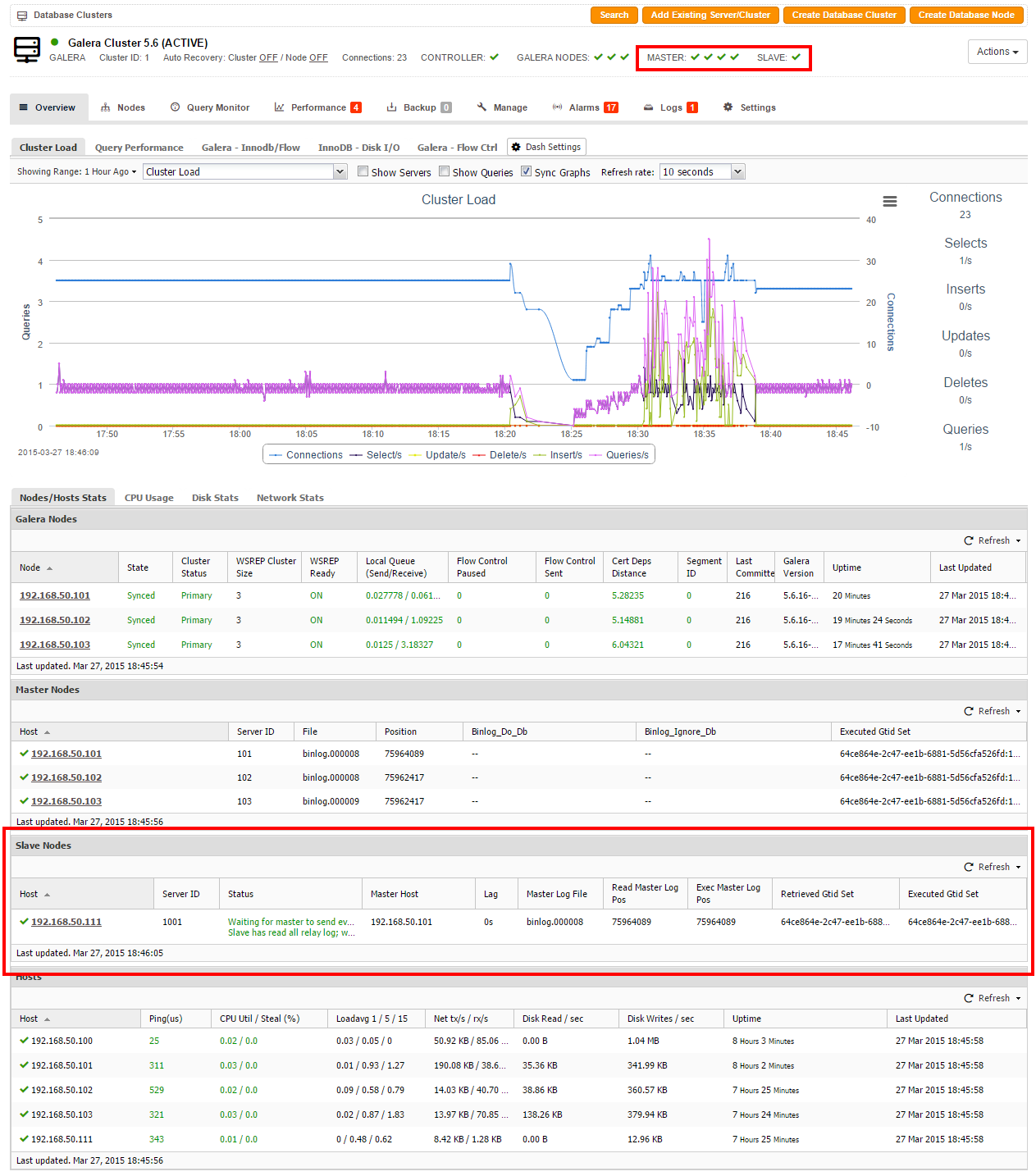
- Determine your cluster ID from the ClusterControl summary bar
- garbd nodes will also need to be upgraded
- All nodes must have internet connection
- ClusterControl auto recovery must been turned off throughout the exercise
To disable ClusterControl auto recovery, add the following line inside /etc/cmon.cnf:
enable_autorecovery=0
And restart CMON service:
$ service cmon restart
Offline Upgrade on Redhat-based Systems
Galera Vendor: Codership
The following steps should be performed on each of the Galera nodes unless specified otherwise.
1. Download MySQL 5.6 server and Galera provider v25.3.x packages from http://galeracluster.com/downloads/:
$ wget https://launchpad.net/codership-mysql/5.6/5.6.16-25.5/+download/MySQL-server-5.6.16_wsrep_25.5-1.rhel6.x86_64.rpm
$ wget https://launchpad.net/galera/3.x/25.3.5/+download/galera-25.3.5-1.rhel6.x86_64.rpm
2. Since we downloaded MySQL Server 5.6.16, we also need to upgrade the MySQL client package from MySQL Community Server archive page with the corresponding version:
$ wget http://downloads.mysql.com/archives/get/file/MySQL-client-5.6.16-1.el6.x86_64.rpm
3. On the ClusterControl node, stop the Galera cluster by using the s9s_galera command with its respective cluster ID. This command will shutdown Galera nodes one at a time and it will not trigger ClusterControl auto recovery. You can determine the cluster ID from the ClusterControl UI summary bar:
$ s9s_galera --stop-cluster -i1
4. Remove the existing MySQL and Galera packages without dependencies:
$ rpm -qa | grep -ie ^mysql -e ^galera | xargs rpm -e --nodeps
5. Install using yum localinstall so it will satisfy all dependencies:
$ yum -y localinstall galera-25.3.5-1.rhel6.x86_64.rpm MySQL-client-5.6.16-1.el6.x86_64.rpm MySQL-server-5.6.16_wsrep_25.5-1.rhel6.x86_64.rpm
For garbd node, just upgrade the Galera package (no need to uninstall it first) and directly kill the garbd process. ClusterControl will then recover the process and it should be started with the new version immediately:
$ yum remove galera
$ yum -y localinstall galera-25.3.5-1.rhel6.x86_64.rpm
$ killall -9 garbd
6. Comment or remove following line inside /etc/my.cnf since it is incompatible with MySQL 5.6:
[MYSQLD]
#engine_condition_pushdown=1
And append the following options recommended for MySQL 5.6:
[MYSQLD]
explicit_defaults_for_timestamp = 1
wsrep_sst_method = xtrabackup-v2
log_error = /var/log/mysqld.log
[MYSQLD_SAFE]
log_error = /var/log/mysqld.log
** In MySQL 5.6, it is recommended to use xtrabackup-v2 as the SST method and change the log_error outside of the MySQL datadir. This is because Xtrabackup would wipe off the MySQL datadir in case of SST.
8. Start the MySQL server with --skip-grant-tables to allow mysql_upgrade:
$ mysqld --skip-grant-tables --user=mysql --wsrep-provider='none'&
Wait for a moment so the MySQL server starts up, and then perform the mysql_upgrade:
$ mysql_upgrade -u root -p
** You should execute mysql_upgrade each time you upgrade MySQL.
9. Kill the running MySQL process:
$ killall -9 mysqld
10. Once all database nodes are upgraded, on the ClusterControl node, start the Galera cluster and specify the last node that shut down as the reference/donor node:
$ s9s_galera --start-cluster -i1 -d 192.168.50.103
Upgrade is now complete. Your Galera cluster will be recovered and available once you re-enable ClusterControl auto recovery feature as described in the last section.
Galera Vendor: Percona
The instructions in this section are based on Percona’s upgrade guide. The following steps should be performed on each of the Galera nodes unless specified otherwise.
1. On the ClusterControl node, stop the Galera cluster by using s9s_galera command with its respective cluster ID. This command will shutdown Galera nodes one at a time. You can determine the cluster ID from ClusterControl UI summary bar:
$ s9s_galera --stop-cluster -i1
2. On the database node, remove the existing MySQL and Galera packages without dependencies:
$ rpm -qa | grep Percona-XtraDB | xargs rpm -e --nodeps
3. Install Percona XtraDB Cluster 5.6 related packages:
$ yum -y install Percona-XtraDB-Cluster-server-56 Percona-XtraDB-Cluster-galera-3
For garbd node, remove the existing garbd v2 and install garbd v3. Then, kill the garbd process. ClusterControl will then recover the process and it should be started with the new version immediately:
$ yum remove Percona-XtraDB-Cluster-garbd*
$ yum -y install Percona-XtraDB-Cluster-garbd-3
$ killall -9 garbd
4. Comment or remove the following line inside /etc/my.cnf since it is incompatible with MySQL 5.6:
[MYSQLD]
#engine_condition_pushdown=1
And append the following options recommended for MySQL 5.6:
[MYSQLD]
explicit_defaults_for_timestamp = 1
wsrep_sst_method = xtrabackup-v2
log_error = /var/log/mysqld.log
[MYSQLD_SAFE]
log_error = /var/log/mysqld.log
** In PXC 5.6, it is recommended to use xtrabackup-v2 as the SST method and change the log_error outside of the MySQL datadir. This is because Xtrabackup would wipe off MySQL datadir in case of SST.
5. Start the MySQL server with --skip-grant-tables to allow mysql_upgrade:
$ mysqld --skip-grant-tables --user=mysql --wsrep-provider='none'&
Wait for a moment so the MySQL starts up, and then perform the mysql_upgrade:
$ mysql_upgrade -u root -p
** You should execute mysql_upgrade each time you upgrade MySQL.
6. Kill the running MySQL process:
$ killall -9 mysqld
7. Once all database nodes are upgraded, on the ClusterControl node, start the Galera cluster and specify the last node that shut down (in this case is 192.168.50.103) as the reference/donor node:
$ s9s_galera --start-cluster -i1 -d 192.168.50.103
Upgrade is now complete. Your Galera cluster will be recovered and available once you re-enable the ClusterControl auto recovery feature as described in the last section.
Galera Vendor: MariaDB
The following steps should be performed on each of the Galera nodes unless specified otherwise.
1. Edit the baseurl value in /etc/yum.repos.d/MariaDB.repo to use MariaDB 10.x repository:
baseurl = http://yum.mariadb.org/10.0/centos6-amd64
Then, remove the yum metadata cache so it will use the latest configured repository instead:
$ yum clean metadata
2. On the ClusterControl node, stop the Galera cluster by using the s9s_galera command with its respective cluster ID. This command will shutdown Galera nodes one at a time. You can determine the cluster ID from the ClusterControl UI summary bar:
$ s9s_galera --stop-cluster -i1
3. Remove the existing MariaDB and Galera packages without dependencies:
$ rpm -qa | grep -e ^MariaDB -e ^galera | xargs rpm -e --nodeps
4. Install MariaDB Galera related packages:
$ yum -y install MariaDB-Galera-server.x86_64 MariaDB-client.x86_64 galera
For garbd node, just upgrade the Galera package (no need to uninstall it first) and directly kill the garbd process. ClusterControl will then recover the process and it should be started with the new version immediately:
$ yum remove galera
$ yum install galera
$ killall -9 garbd
5. The previous MySQL configuration will be saved as /etc/my.cnf.rpmsave. Reuse the file by renaming it to /etc/my.cnf:
$ mv /etc/my.cnf.rpmsave /etc/my.cnf
6. Comment or remove the following line in /etc/my.cnf since it is incompatible with MariaDB 10.x:
[MYSQLD]
#engine_condition_pushdown=1
And append the following options recommended for MariaDB 10.x:
[MYSQLD]
wsrep_sst_method = xtrabackup-v2
log_error = /var/log/mysqld.log
[MYSQLD_SAFE]
log_error = /var/log/mysqld.log
** In MariaDB 10, it is recommended to use xtrabackup-v2 as the SST method and change the log_error outside of the MySQL datadir. This is because Xtrabackup would wipe off MySQL datadir in case of SST.
7. Start the MariaDB server with --skip-grant-tables to allow mysql_upgrade:
$ mysqld --skip-grant-tables --user=mysql --wsrep-provider='none'&
And then perform the mysql_upgrade:
$ mysql_upgrade -u root -p
** You should execute mysql_upgrade each time you upgrade MariaDB.
8. Kill the running MariaDB process:
$ killall -9 mysqld
9. Once all database nodes are upgraded, on the ClusterControl node, start the Galera cluster and specify the last node that shut down as the reference/donor node:
$ s9s_galera --start-cluster -i1 -d 192.168.50.103
Upgrade is now complete. Your Galera cluster will be recovered and available once you re-enable ClusterControl auto recovery feature as described in the last section.
Offline Upgrade on Debian-based systems
Galera Vendor: Codership
If you deployed Galera cluster using the Severalnines Configurator, you would have had MySQL 5.5 installed using tarball under directory /usr/local/mysql. In MySQL 5.6, we urge users to use the DEB package instead, so expect the MySQL basedir to change to /usr, as shown in the instructions below.
The following steps should be performed on each of the Galera nodes unless specified otherwise. Omit sudo if you run as root.
1. Download MySQL 5.6 server and Galera provider v25.3.x packages from http://galeracluster.com/downloads/:
$ wget https://launchpad.net/codership-mysql/5.6/5.6.16-25.5/+download/mysql-server-wsrep-5.6.16-25.5-amd64.deb
$ wget https://launchpad.net/galera/3.x/25.3.5/+download/galera-25.3.5-amd64.deb
2. Install a third-party MySQL 5.6 package repository to facilitate the installation:
$ sudo apt-get -y install software-properties-common python-software-properties
$ sudo add-apt-repository -y ppa:ondrej/mysql-5.6
$ sudo apt-get update
3. On the ClusterControl node, stop the Galera cluster by using the s9s_galera command with its respective cluster ID. This command will shutdown the Galera nodes one at a time. You can determine the cluster ID from the ClusterControl UI summary bar:
$ sudo s9s_galera --stop-cluster -i1
4. Install the MySQL 5.6 client package from repository, install the downloaded MySQL Server 5.6 and Galera packages:
$ sudo apt-get -y install mysql-client-5.6
$ sudo dpkg -i mysql-server-wsrep-5.6.16-25.5-amd64.deb
$ sudo dpkg -i galera-25.3.5-amd64.deb
** Accept the default value for any prompt during apt-get install command
For garbd node, just upgrade the Galera package (no need to uninstall it first) and directly kill the garbd process. ClusterControl will then recover the process and it should start with the new version immediately:
$ sudo dpkg -i galera-25.3.5-amd64.deb
$ sudo killall -9 garbd
5. Comment or remove the following line inside /etc/mysql/my.cnf since it is incompatible with MySQL 5.6:
[MYSQLD]
#engine_condition_pushdown=1
And append following options recommended for MySQL 5.6:
[MYSQLD]
basedir = /usr
explicit_defaults_for_timestamp = 1
log_error = /var/log/mysql.log
[MYSQLD_SAFE]
basedir = /usr
log_error = /var/log/mysql.log
** The basedir has changed to /usr with the new DEB package installation. It is recommended to change the log_error outside of the MySQL datadir. This is because Xtrabackup would wipe off MySQL datadir in case of SST.
6. Start the MySQL server with --skip-grant-tables to allow mysql_upgrade:
$ sudo mysqld --skip-grant-tables --user=mysql --wsrep-provider='none'&
And then perform the mysql_upgrade:
$ mysql_upgrade -u root -p
** You should execute mysql_upgrade each time you upgrade MySQL.
7. Terminate the MySQL server for mysql_upgrade:
$ sudo killall -9 mysqld
8. Once all database nodes are upgraded, on the ClusterControl node, start the Galera cluster and specify the last node that shut down as the reference/donor node:
$ sudo s9s_galera --start-cluster -i1 -d 192.168.50.103
Upgrade is now complete. Your Galera cluster will be recovered and available once you re-enable ClusterControl auto recovery feature as described in the last section.
Once all Galera nodes are up, you can safely remove the previous MySQL 5.5 installation under /usr/local:
$ sudo rm -Rf /usr/local/mysql*
Galera Vendor: Percona
The instructions in this section are based on Percona’s upgrade guide. The following steps should be performed on each of the Galera nodes unless specified otherwise. Omit sudo if you run as root.
1. On the ClusterControl node, stop the Galera cluster by using the s9s_galera command with its respective cluster ID. This command will shutdown the Galera nodes one at a time. You can determine the cluster ID from the ClusterControl UI summary bar:
$ sudo s9s_galera --stop-cluster -i1
2. On the database node, remove the existing MySQL and Galera packages:
$ sudo apt-get remove percona-xtradb-cluster-server-5.5 percona-xtradb-cluster-galera-2.x percona-xtradb-cluster-common-5.5 percona-xtradb-cluster-client-5.5
3. Comment the following lines in /etc/mysql/my.cnf:
[MYSQLD]
#engine_condition_pushdown=1
#wsrep_provider=/usr/lib/libgalera_smm.so
And append the following options recommended for MySQL 5.6:
[MYSQLD]
explicit_defaults_for_timestamp = 1
wsrep_sst_method = xtrabackup-v2
log_error = /var/log/mysql.log
wsrep_provider=none
[MYSQLD_SAFE]
log_error = /var/log/mysql.log
** In PXC 5.6, it is recommended to use xtrabackup-v2 as the SST method and change the log_error outside of the MySQL datadir. This is because Xtrabackup would wipe off the MySQL datadir in case of SST.
4. Install Percona XtraDB Cluster 5.6 related packages:
$ sudo LC_ALL=en_US.utf8 DEBIAN_FRONTEND=noninteractive apt-get -o Dpkg::Options::='--force-confnew' -y install percona-xtradb-cluster-56
For garbd node, remove the existing garbd v2 and install garbd v3. Then, kill the garbd process. ClusterControl will then recover the process and it should be started with the new version immediately:
$ sudo sed -i '1 a\exit 0 #temp_workaround' /etc/init.d/garbd
$ sudo LC_ALL=en_US.utf8 DEBIAN_FRONTEND=noninteractive apt-get -o Dpkg::Options::='--force-confnew' -y install percona-xtradb-cluster-garbd-3.x
$ sudo sed -i '/exit 0 #temp_workaround/d' /etc/init.d/garbd
$ killall -9 garbd
5. Perform the mysql_upgrade command:
$ mysql_upgrade -u root -p
** You should execute mysql_upgrade each time you upgrade MySQL.
6. Kill the running MySQL process:
$ sudo service mysql stop
7. Uncomment the following line in /etc/mysql/my.cnf:
wsrep_provider=/usr/lib/libgalera_smm.so
And remove or comment the following line:
#wsrep_provider=none
8. Once all database nodes are upgraded, on the ClusterControl node, start the Galera cluster and specify the last node that shut down (in this case is 192.168.50.103) as the reference/donor node:
$ sudo s9s_galera --start-cluster -i1 -d 192.168.50.103
Upgrade is now complete. Your Galera cluster will be recovered and available once you re-enable ClusterControl auto recovery feature as described in the last section.
Galera Vendor: MariaDB
The following steps should be performed on each of the Galera nodes unless specified otherwise. Omit sudo if you run as root.
1. Edit the repository URL in /etc/apt/sources.list.d/MariaDB.list to use MariaDB 10.x repository, similar to below:
deb http://ftp.osuosl.org/pub/mariadb/repo/10.0/ubuntu precise main
deb-src http://ftp.osuosl.org/pub/mariadb/repo/10.0/ubuntu precise main
Then, update the package lists:
$ sudo apt-get update
2. On the ClusterControl node, stop the Galera cluster by using the s9s_galera command with its respective cluster ID. This command will shutdown Galera nodes one at a time. You can determine the cluster ID from the ClusterControl UI summary bar:
$ sudo s9s_galera --stop-cluster -i1
3. Remove the existing MariaDB and Galera packages:
$ sudo apt-get remove mariadb-galera-server-5.5 mariadb-client-5.5 galera
4. Comment the following line inside /etc/mysql/my.cnf:
[MYSQLD]
#engine_condition_pushdown=1
#wsrep_provider=/usr/lib/galera/libgalera_smm.so
And append the following options recommended for MariaDB 10.x:
[MYSQLD]
wsrep_sst_method = xtrabackup-v2
log_error = /var/log/mysql.log
wsrep_provider=none
[MYSQLD_SAFE]
log_error = /var/log/mysql.log
** In MariaDB 10, it is recommended to use xtrabackup-v2 as the SST method and change the log_error outside of the MySQL datadir. This is because Xtrabackup would wipe off the MySQL datadir in case of SST.
4. Install MariaDB 10.x related packages:
$ sudo LC_ALL=en_US.utf8 DEBIAN_FRONTEND=noninteractive apt-get -o Dpkg::Options::='--force-confnew' -y install mariadb-galera-server galera
For garbd node, remove the existing garbd v2 and install garbd v3. Then, kill the garbd process. ClusterControl will recover the process and it should be started with the new version immediately:
$ sudo apt-get remove galera
$ sudo LC_ALL=en_US.utf8 DEBIAN_FRONTEND=noninteractive apt-get -o Dpkg::Options::='--force-confnew' -y galera
$ sudo killall -9 garbd
5. Execute mysql_upgrade command:
$ mysql_upgrade -u root -p
6. Kill the running MySQL process:
$ sudo service mysql stop
7. Uncomment the following line in /etc/mysql/my.cnf:
wsrep_provider=/usr/lib/galera/libgalera_smm.so
And remove or comment the following line:
#wsrep_provider=none
8. Once all database nodes are upgraded, on the ClusterControl node, start the Galera cluster and specify the last node that shut down (in this case is 192.168.50.103) as the reference/donor node:
$ sudo s9s_galera --start-cluster -i1 -d 192.168.50.103
Upgrade is now complete. Your Galera cluster will be recovered and available once you re-enable ClusterControl auto recovery feature as described in the last section.
Post-Upgrade
ClusterControl
Enable back ClusterControl auto recovery feature by removing/commenting the following line in CMON configuration file:
enable_autorecovery=0
Restart CMON service to apply the change.
In certain cases, the changes that we made manually to the MySQL configuration file might not appear in ClusterControl > Manage > Configuration. To reimport the latest configuration file from the Galera nodes, go to ClusterControl > Manage > Configurations > Reimport Configuration. Wait for a moment before ClusterControl starts updating the detected database server version under ClusterControl > Settings > General Settings > Version. If the version is not updated after a few minutes, restart the CMON service to expedite this.
WAN Segments
MySQL 5.6/MariaDB 10 with Galera 3.x supports WAN segmentation. If you are running on WAN, you can take advantage of this feature by assigning the same segment ID to nodes located in the same data center. Append the following to your MySQL configuration:
wsrep_provider_options="gmcast.segment=2"
* If you have configuration options under wsrep_provider_options eg: wsrep_provider_options="gcache.size=128M", you need to append it to the line separated by a semi-colon:
wsrep_provider_options="gcache.size=128M;gmcast.segment=2"
Welcome to MySQL 5.6/MariaDB 10!